Nucleotide Sequence (with vector) for pF1KSDA1142
Download
>pF1KSDA1142 4451 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT
AGAACCATGTTTGGGAAGAGGAAGAAGCGGGTGGAGATCTCCGCGCCGTCCAACTTCGAG
CACCGCGTGCACACGGGCTTCGACCAGCACGAGCAGAAGTTCACGGGGCTGCCCCGCCAG
TGGCAGAGCCTGATCGAGGAGTCGGCTCGCCGGCCCAAGCCCCTCGTCGACCCCGCCTGC
ATCACCTCCATCCAGCCCGGGGCCCCCAAGGGGGAGCCTCATGACGTGGCCCCTAACGGG
CCATCAGCGGGGGGCCTGGCCATCCCCCAGTCCTCCTCCTCCTCCTCCCGGCCTCCCACC
CGAGCCCGAGGTGCCCCCAGCCCTGGAGTGCTGGGACCCCACGCCTCAGAGCCCCAGCTG
GCCCCTCCAGCCTGCACCCCCGCCGCCCCTGCTGTTCCTGGGCCCCCTGGCCCCCGCTCA
CCACAGCGGGAGCCACAGCGAGTATCCCATGAGCAGTTCCGGGCTGCCCTGCAGCTGGTG
GTGGACCCAGGCGACCCCCGCTCCTACCTGGACAACTTCATCAAGATTGGCGAGGGCTCC
ACGGGCATCGTGTGCATCGCCACCGTGCGCAGCTCGGGCAAGCTGGTGGCCGTCAAGAAG
ATGGACCTGCGCAAGCAGCAGAGGCGCGAGCTGCTCTTCAACGAGGTGGTAATCATGAGG
GACTACCAGCACGAGAATGTGGTGGAGATGTACAACAGCTACCTGGTGGGGGACGAGCTC
TGGGTGGTCATGGAGTTCCTGGAAGGAGGCGCCCTCACCGACATCGTCACCCACACCAGG
ATGAACGAGGAGCAGATCGCGGCCGTGTGCCTTGCAGTGCTGCAGGCCCTGTCGGTGCTC
CACGCCCAGGGCGTCATCCACCGGGACATCAAGAGCGACTCGATCCTGCTGACCCATGAT
GGCAGGGTGAAGCTGTCAGACTTTGGGTTCTGCGCCCAGGTGAGCAAGGAAGTGCCCCGA
AGGAAGTCGCTGGTCGGCACGCCCTACTGGATGGCCCCAGAGCTCATCTCCCGCCTTCCC
TACGGGCCAGAGGTAGACATCTGGTCGCTGGGGATAATGGTGATTGAGATGGTGGACGGA
GAGCCCCCCTACTTCAACGAGCCACCCCTCAAAGCCATGAAGATGATTCGGGACAACCTG
CCACCCCGACTGAAGAACCTGCACAAGGTGTCGCCATCCCTGAAGGGCTTCCTGGACCGC
CTGCTGGTGCGAGACCCTGCCCAGCGGGCCACGGCAGCCGAGCTGCTGAAGCACCCATTC
CTGGCCAAGGCAGGGCCGCCTGCCAGCATCGTGCCCCTCATGCGCCAGAACCGCACCAGA
TACGTAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGG
CATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCAC
CGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTT
GCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTA
TCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGT
CCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTT
CTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCT
TCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAAC
TGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAG
ACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCC
GCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGAT
GCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTG
TCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACG
GGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTA
TTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTA
TCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTC
GACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTC
GATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGG
CTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTG
CCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGT
GTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGC
GGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGC
ATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGA
CCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCAC
AGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAA
CCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCA
CAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGC
GTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATA
CCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTA
TCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCA
GCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGA
CTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGG
TGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGG
TATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGG
CAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAG
AAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAA
CGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGAT
CCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAA
ACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGG
TTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTG
GTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGC
GTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAA
ACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGAT
ACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAG
CGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGG
TAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGG
CTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGA
GTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGC
GGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGG
ATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATG
TATCCGCTCAT



 Length: 1314 bp
Length: 1314 bp Restriction map B
Restriction map B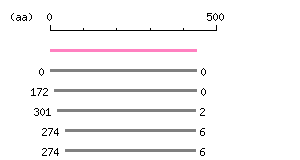

 more Linker info
more Linker info
{kind=link}