


-
SpecieshumanProduct IDFXC20056Cloning SiteSgfI-PmeIGenBank AccessionGeneKIBB9400SymbolTAS1R1
Alias : GM148, GPR70, T1R1, TR1Descriptiontaste receptor, type 1, member 1, transcript variant 2Original Clone IDcp02288 Length: 2523 bp
Length: 2523 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 841 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
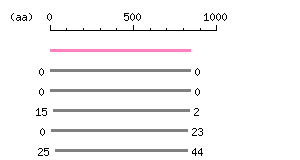
Entry Exp ID% symbol CCDS81.1 0 99.9 TAS1R1 CCDS82.1 5.4e-165 69.8 TAS1R1 CCDS187.1 2.8e-101 37.3 TAS1R2 CCDS30556.1 2.2e-84 32.8 TAS1R3 CCDS2834.1 2.5e-44 28.5 GRM2
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]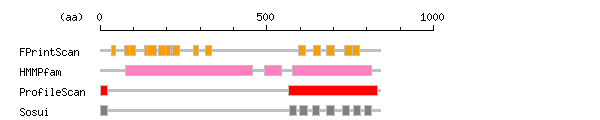 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition FPrintScan IPR000337 35 47 PR00248 GPCR IPR000337 72 87 PR00248 GPCR IPR000337 87 106 PR00248 GPCR IPR000068 132 145 PR00592 GPCR IPR000337 143 169 PR00248 GPCR IPR000337 176 195 PR00248 GPCR IPR000337 195 211 PR00248 GPCR IPR000337 211 228 PR00248 GPCR IPR000068 217 238 PR00592 GPCR IPR000068 281 296 PR00592 GPCR IPR000068 317 335 PR00592 GPCR IPR000337 594 616 PR00248 GPCR IPR000337 639 660 PR00248 GPCR IPR000337 679 702 PR00248 GPCR IPR000337 734 757 PR00248 GPCR IPR000337 757 778 PR00248 GPCR HMMPfam IPR001828 76 456 PF01094 Extracellular ligand-binding receptor IPR011500 493 545 PF07562 GPCR IPR017978 577 815 PF00003 GPCR ProfileScan NULL 1 23 PS51257 NULL IPR017978 566 831 PS50259 GPCR
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 2 LLCTARLVGLQLLISCCWAFAC 23 PRIMARY 22 2 568 WVLLAANTLLLLLLLGTAGLFAW 590 PRIMARY 23 3 599 SAGGRLCFLMLGSLAAGSGSLYG 621 SECONDARY 23 4 637 LFALGFTIFLSCLTVRSFQLIII 659 PRIMARY 23 5 680 GLFVMISSAAQLLICLTWLVVWT 702 PRIMARY 23 6 726 LGFILAFLYNGLLSISAFACSYL 748 SECONDARY 23 7 760 KCVTFSLLFNFVSWIAFFTTASV 782 PRIMARY 23 8 792 NMMAGLSSLSSGFGGYFLPKCYV 814 SECONDARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_619642 841 606225 99.9 100.0 XP_016857891 843 606225 96.9 96.2 XP_011540505 763 606225 99.9 90.7 NP_803884 587 606225 69.8 100.0 XP_016857892 589 606225 65.6 96.2 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KB9400 Download>KIBB9400 2523 bp ATGCTGCTCTGCACGGCTCGCCTGGTCGGCCTGCAGCTTCTCATTTCCTGCTGCTGGGCC TTTGCCTGCCATAGCACGGAGTCTTCTCCTGACTTCACCCTCCCCGGAGATTACCTCCTG GCAGGCCTGTTCCCTCTCCATTCTGGCTGTCTGCAGGTGAGGCACAGACCCGAGGTGACC CTGTGTGACAGGTCTTGTAGCTTCAATGAGCATGGCTACCACCTCTTCCAGGCTATGCGG CTTGGGGTTGAGGAGATAAACAACTCCACGGCCCTGCTGCCCAACATCACCCTGGGGTAC CAGCTGTATGATGTGTGTTCTGACTCTGCCAATGTGTATGCCACGCTGAGAGTGCTCTCC CTGCCAGGGCAACACCACATAGAGCTCCAAGGAGACCTTCTCCACTATTCCCCTACGGTG CTGGCAGTGATTGGGCCTGACAGCACCAACCGTGCTGCCACCACAGCCGCCCTGCTGAGC CCTTTCCTGGTGCCCATGATTAGCTATGCGGCCAGCAGCGAGACGCTCAGCGTGAAGCGG CAGTATCCCTCTTTCCTGCGCACCATCCCCAATGACAAGTACCAGGTGGAGACCATGGTG CTGCTGCTGCAGAAGTTCGGGTGGACCTGGATCTCTCTGGTTGGCAGCAGTGACGACTAT GGGCAGCTAGGGGTGCAGGCACTGGAGAACCAGGCCACTGGTCAGGGGATCTGCATTGCT TTCAAGGACATCATGCCCTTCTCTGCCCAGGTGGGCGATGAGAGGATGCAGTGCCTCATG CGCCACCTGGCCCAGGCCGGGGCCACCGTCGTGGTTGTTTTTTCCAGCCGGCAGTTGGCC AGGGTGTTTTTCGAGTCCGTGGTGCTGACCAACCTGACTGGCAAGGTGTGGGTCGCCTCA GAAGCCTGGGCCCTCTCCAGGCACATCACTGGGGTGCCCGGGATCCAGCGCATTGGGATG GTGCTGGGCGTGGCCATCCAGAAGAGGGCTGTCCCTGGCCTGAAGGCGTTTGAAGAAGCC TATGCCCGGGCAGACAAGGAGGCCCCTAGGCCTTGCCACAAGGGCTCCTGGTGCAGCAGC AATCAGCTCTGCAGAGAATGCCAAGCTTTCATGGCACACACGATGCCCAAGCTCAAAGCC TTCTCCATGAGTTCTGCCTACAACGCATACCGGGCTGTGTATGCGGTGGCCCATGGCCTC CACCAGCTCCTGGGCTGTGCCTCTGGAGCTTGTTCCAGGGGCCGAGTCTACCCCTGGCAG CTTTTGGAGCAGATCCACAAGGTGCATTTCCTTCTACACAAGGACACTGTGGCGTTTAAT GACAACAGAGATCCCCTCAGTAGCTATAACATAATTGCCTGGGACTGGAATGGACCCAAG TGGACCTTCACGGTCCTCGGTTCCTCCACATGGTCTCCAGTTCAGCTAAACATAAATGAG ACCAAAATCCAGTGGCACGGAAAGGACAACCAGGTGCCTAAGTCTGTGTGTTCCAGCGAC TGTCTTGAAGGGCACCAGCGAGTGGTTACGGGTTTCCATCACTGCTGCTTTGAGTGTGTG CCCTGTGGGGCTGGGACCTTCCTCAACAAGAGTGACCTCTACAGATGCCAGCCTTGTGGG AAAGAAGAGTGGGCACCTGAGGGAAGCCAGACCTGCTTCCCGCGCACTGTGGTGTTTTTG GCTTTGCGTGAGCACACCTCTTGGGTGCTGCTGGCAGCTAACACGCTGCTGCTGCTGCTG CTGCTTGGGACTGCTGGCCTGTTTGCCTGGCACCTAGACACCCCTGTGGTGAGGTCAGCA GGGGGCCGCCTGTGCTTTCTTATGCTGGGCTCCCTGGCAGCAGGTAGTGGCAGCCTCTAT GGCTTCTTTGGGGAACCCACAAGGCCTGCGTGCTTGCTACGCCAGGCCCTCTTTGCCCTT GGTTTCACCATCTTCCTGTCCTGCCTGACAGTTCGCTCATTCCAACTAATCATCATCTTC AAGTTTTCCACCAAGGTACCTACATTCTACCACGCCTGGGTCCAAAACCACGGTGCTGGC CTGTTTGTGATGATCAGCTCAGCGGCCCAGCTGCTTATCTGTCTAACTTGGCTGGTGGTG TGGACCCCACTGCCTGCTAGGGAATACCAGCGCTTCCCCCATCTGGTGATGCTTGAGTGC ACAGAGACCAACTCCCTGGGCTTCATACTGGCCTTCCTCTACAATGGCCTCCTCTCCATC AGTGCCTTTGCCTGCAGCTACCTGGGTAAGGACTTGCCAGAGAACTACAACGAGGCCAAA TGTGTCACCTTCAGCCTGCTCTTCAACTTCGTGTCCTGGATCGCCTTCTTCACCACGGCC AGCGTCTACGACGGCAAGTACCTGCCTGCGGCCAACATGATGGCTGGGCTGAGCAGCCTG AGCAGCGGCTTCGGTGGGTATTTTCTGCCTAAGTGCTACGTGATCCTCTGCCGCCCAGAC CTCAACAGCACAGAGCACTTCCAGGCCTCCATTCAGGACTACACGAGGCGCTGCGGCTCC ACC
Cloned ORF protein sequence for pF1KB9400 Download>KIBB9400 841 aa MLLCTARLVGLQLLISCCWAFACHSTESSPDFTLPGDYLLAGLFPLHSGCLQVRHRPEVT LCDRSCSFNEHGYHLFQAMRLGVEEINNSTALLPNITLGYQLYDVCSDSANVYATLRVLS LPGQHHIELQGDLLHYSPTVLAVIGPDSTNRAATTAALLSPFLVPMISYAASSETLSVKR QYPSFLRTIPNDKYQVETMVLLLQKFGWTWISLVGSSDDYGQLGVQALENQATGQGICIA FKDIMPFSAQVGDERMQCLMRHLAQAGATVVVVFSSRQLARVFFESVVLTNLTGKVWVAS EAWALSRHITGVPGIQRIGMVLGVAIQKRAVPGLKAFEEAYARADKEAPRPCHKGSWCSS NQLCRECQAFMAHTMPKLKAFSMSSAYNAYRAVYAVAHGLHQLLGCASGACSRGRVYPWQ LLEQIHKVHFLLHKDTVAFNDNRDPLSSYNIIAWDWNGPKWTFTVLGSSTWSPVQLNINE TKIQWHGKDNQVPKSVCSSDCLEGHQRVVTGFHHCCFECVPCGAGTFLNKSDLYRCQPCG KEEWAPEGSQTCFPRTVVFLALREHTSWVLLAANTLLLLLLLGTAGLFAWHLDTPVVRSA GGRLCFLMLGSLAAGSGSLYGFFGEPTRPACLLRQALFALGFTIFLSCLTVRSFQLIIIF KFSTKVPTFYHAWVQNHGAGLFVMISSAAQLLICLTWLVVWTPLPAREYQRFPHLVMLEC TETNSLGFILAFLYNGLLSISAFACSYLGKDLPENYNEAKCVTFSLLFNFVSWIAFFTTA SVYDGKYLPAANMMAGLSSLSSGFGGYFLPKCYVILCRPDLNSTEHFQASIQDYTRRCGS T
Nucleotide Sequence (with vector) for pF1KB9400 Download>pF1KB9400 5636 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGCTGCTCTGC ACGGCTCGCCTGGTCGGCCTGCAGCTTCTCATTTCCTGCTGCTGGGCCTTTGCCTGCCAT AGCACGGAGTCTTCTCCTGACTTCACCCTCCCCGGAGATTACCTCCTGGCAGGCCTGTTC CCTCTCCATTCTGGCTGTCTGCAGGTGAGGCACAGACCCGAGGTGACCCTGTGTGACAGG TCTTGTAGCTTCAATGAGCATGGCTACCACCTCTTCCAGGCTATGCGGCTTGGGGTTGAG GAGATAAACAACTCCACGGCCCTGCTGCCCAACATCACCCTGGGGTACCAGCTGTATGAT GTGTGTTCTGACTCTGCCAATGTGTATGCCACGCTGAGAGTGCTCTCCCTGCCAGGGCAA CACCACATAGAGCTCCAAGGAGACCTTCTCCACTATTCCCCTACGGTGCTGGCAGTGATT GGGCCTGACAGCACCAACCGTGCTGCCACCACAGCCGCCCTGCTGAGCCCTTTCCTGGTG CCCATGATTAGCTATGCGGCCAGCAGCGAGACGCTCAGCGTGAAGCGGCAGTATCCCTCT TTCCTGCGCACCATCCCCAATGACAAGTACCAGGTGGAGACCATGGTGCTGCTGCTGCAG AAGTTCGGGTGGACCTGGATCTCTCTGGTTGGCAGCAGTGACGACTATGGGCAGCTAGGG GTGCAGGCACTGGAGAACCAGGCCACTGGTCAGGGGATCTGCATTGCTTTCAAGGACATC ATGCCCTTCTCTGCCCAGGTGGGCGATGAGAGGATGCAGTGCCTCATGCGCCACCTGGCC CAGGCCGGGGCCACCGTCGTGGTTGTTTTTTCCAGCCGGCAGTTGGCCAGGGTGTTTTTC GAGTCCGTGGTGCTGACCAACCTGACTGGCAAGGTGTGGGTCGCCTCAGAAGCCTGGGCC CTCTCCAGGCACATCACTGGGGTGCCCGGGATCCAGCGCATTGGGATGGTGCTGGGCGTG GCCATCCAGAAGAGGGCTGTCCCTGGCCTGAAGGCGTTTGAAGAAGCCTATGCCCGGGCA GACAAGGAGGCCCCTAGGCCTTGCCACAAGGGCTCCTGGTGCAGCAGCAATCAGCTCTGC AGAGAATGCCAAGCTTTCATGGCACACACGATGCCCAAGCTCAAAGCCTTCTCCATGAGT TCTGCCTACAACGCATACCGGGCTGTGTATGCGGTGGCCCATGGCCTCCACCAGCTCCTG GGCTGTGCCTCTGGAGCTTGTTCCAGGGGCCGAGTCTACCCCTGGCAGCTTTTGGAGCAG ATCCACAAGGTGCATTTCCTTCTACACAAGGACACTGTGGCGTTTAATGACAACAGAGAT CCCCTCAGTAGCTATAACATAATTGCCTGGGACTGGAATGGACCCAAGTGGACCTTCACG GTCCTCGGTTCCTCCACATGGTCTCCAGTTCAGCTAAACATAAATGAGACCAAAATCCAG TGGCACGGAAAGGACAACCAGGTGCCTAAGTCTGTGTGTTCCAGCGACTGTCTTGAAGGG CACCAGCGAGTGGTTACGGGTTTCCATCACTGCTGCTTTGAGTGTGTGCCCTGTGGGGCT GGGACCTTCCTCAACAAGAGTGACCTCTACAGATGCCAGCCTTGTGGGAAAGAAGAGTGG GCACCTGAGGGAAGCCAGACCTGCTTCCCGCGCACTGTGGTGTTTTTGGCTTTGCGTGAG CACACCTCTTGGGTGCTGCTGGCAGCTAACACGCTGCTGCTGCTGCTGCTGCTTGGGACT GCTGGCCTGTTTGCCTGGCACCTAGACACCCCTGTGGTGAGGTCAGCAGGGGGCCGCCTG TGCTTTCTTATGCTGGGCTCCCTGGCAGCAGGTAGTGGCAGCCTCTATGGCTTCTTTGGG GAACCCACAAGGCCTGCGTGCTTGCTACGCCAGGCCCTCTTTGCCCTTGGTTTCACCATC TTCCTGTCCTGCCTGACAGTTCGCTCATTCCAACTAATCATCATCTTCAAGTTTTCCACC AAGGTACCTACATTCTACCACGCCTGGGTCCAAAACCACGGTGCTGGCCTGTTTGTGATG ATCAGCTCAGCGGCCCAGCTGCTTATCTGTCTAACTTGGCTGGTGGTGTGGACCCCACTG CCTGCTAGGGAATACCAGCGCTTCCCCCATCTGGTGATGCTTGAGTGCACAGAGACCAAC TCCCTGGGCTTCATACTGGCCTTCCTCTACAATGGCCTCCTCTCCATCAGTGCCTTTGCC TGCAGCTACCTGGGTAAGGACTTGCCAGAGAACTACAACGAGGCCAAATGTGTCACCTTC AGCCTGCTCTTCAACTTCGTGTCCTGGATCGCCTTCTTCACCACGGCCAGCGTCTACGAC GGCAAGTACCTGCCTGCGGCCAACATGATGGCTGGGCTGAGCAGCCTGAGCAGCGGCTTC GGTGGGTATTTTCTGCCTAAGTGCTACGTGATCCTCTGCCGCCCAGACCTCAACAGCACA GAGCACTTCCAGGCCTCCATTCAGGACTACACGAGGCGCTGCGGCTCCACCGTTTAAACG AATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCC GGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACT AGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAAC TATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCC ACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTA GCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTT CCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCA GCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTG CCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCG TTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGG CTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGG CTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAAT GAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCA GCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCG GGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGAT GCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAA CATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTG GACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATG CCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTG GAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTAT CAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGAC CGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGC CTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGC CCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAA CGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGC GTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTC AAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAG CTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCT CCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTA GGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGC CTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGC AGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTT GAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCT GAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGC TGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCA AGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTA AGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGG AAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGC AGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCA TACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTT TACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGAT TATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGG CCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGA ACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACC TGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCC CCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACT GGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGC CGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGC CATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGT TTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}