Nucleotide Sequence (with vector) for pF1KB8492
Download
>pF1KB8492 5687 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGTGAACTTC
ACGGTAGACCAGATCCGCGCCATCATGGACAAGAAGGCCAACATCCGCAACATGTCTGTC
ATCGCCCACGTGGACCATGGCAAGTCCACGCTGACAGACTCCCTGGTGTGCAAGGCGGGC
ATCATCGCCTCGGCCCGGGCCGGGGAGACACGCTTCACTGATACCCGGAAGGACGAGCAG
GAGCGTTGCATCACCATCAAGTCAACTGCCATCTCCCTCTTCTACGAGCTCTCGGAGAAT
GACTTGAACTTCATCAAGCAGAGCAAGGACGGTGCCGGCTTCCTCATCAACCTCATTGAC
TCCCCCGGGCATGTCGACTTCTCCTCGGAGGTGACTGCTGCCCTCCGAGTCACCGATGGC
GCATTGGTGGTGGTGGACTGCGTGTCAGGCGTGTGCGTGCAGACGGAGACAGTGCTGCGG
CAGGCCATTGCCGAGCGCATCAAGCCTGTGCTGATGATGAACAAGATGGACCGCGCCCTG
CTGGAGCTGCAGCTGGAGCCCGAGGAGCTCTACCAGACTTTCCAGCGCATCGTGGAGAAC
GTGAACGTCATCATCTCCACCTACGGCGAGGGCGAGAGCGGCCCCATGGGCAACATCATG
ATCGATCCTGTCCTCGGTACCGTGGGCTTTGGGTCTGGCCTCCACGGGTGGGCCTTCACC
CTGAAGCAGTTTGCCGAGATGTATGTGGCCAAGTTCGCCGCCAAGGGGGAGGGCCAGTTG
GGGCCTGCCGAGCGGGCCAAGAAAGTAGAGGACATGATGAAGAAGCTGTGGGGTGACAGG
TACTTTGACCCAGCCAACGGCAAGTTCAGCAAGTCAGCCACCAGCCCCGAAGGGAAGAAG
CTGCCACGCACCTTCTGCCAGCTGATCCTGGACCCCATCTTCAAGGTGTTTGATGCGATC
ATGAATTTCAAGAAAGAGGAGACAGCAAAACTGATAGAGAAACTGGACATCAAACTGGAC
AGCGAGGACAAGGACAAAGAAGGCAAACCCCTGCTGAAGGCTGTGATGCGCCGCTGGCTG
CCTGCCGGAGACGCCTTGTTGCAGATGATCACCATCCACCTGCCCTCCCCTGTGACGGCC
CAGAAGTACCGCTGCGAGCTCCTGTACGAGGGGCCCCCGGACGACGAGGCTGCCATGGGC
ATTAAAAGCTGTGACCCCAAAGGCCCTCTTATGATGTATATTTCCAAAATGGTGCCAACC
TCCGACAAAGGTCGGTTCTACGCCTTTGGACGAGTCTTCTCGGGGCTGGTCTCCACTGGC
CTGAAGGTCAGGATCATGGGGCCCAACTATACCCCTGGGAAGAAGGAGGACCTCTACCTG
AAGCCAATCCAGAGAACAATCTTGATGATGGGCCGCTACGTGGAGCCCATCGAGGATGTG
CCTTGTGGGAACATTGTGGGCCTCGTGGGCGTGGACCAGTTCCTGGTGAAGACGGGCACC
ATCACCACCTTCGAGCACGCGCACAACATGCGGGTGATGAAGTTCAGCGTCAGCCCTGTT
GTCAGAGTGGCCGTGGAGGCCAAGAACCCGGCTGACCTGCCCAAGCTGGTGGAGGGGCTG
AAGCGGCTGGCCAAGTCCGACCCCATGGTGCAGTGCATCATCGAGGAGTCGGGAGAGCAT
ATCATCGCGGGCGCCGGCGAGCTGCACCTGGAGATCTGCCTGAAGGACCTGGAGGAGGAC
CACGCCTGCATCCCCATCAAGAAATCTGACCCGGTCGTCTCGTACCGCGAGACGGTCAGT
GAAGAGTCGAACGTGCTCTGCCTCTCCAAGTCCCCCAACAAGCACAACCGGCTGTACATG
AAGGCGCGGCCCTTCCCCGACGGCCTGGCCGAGGACATCGATAAAGGCGAGGTGTCCGCC
CGTCAGGAGCTCAAGCAGCGGGCGCGCTACCTGGCCGAGAAGTACGAGTGGGACGTGGCT
GAGGCCCGCAAGATCTGGTGCTTTGGGCCCGACGGCACCGGCCCCAACATCCTCACCGAC
ATCACCAAGGGTGTGCAGTACCTCAACGAGATCAAGGACAGTGTGGTGGCCGGCTTCCAG
TGGGCCACCAAGGAGGGCGCACTGTGTGAGGAGAACATGCGGGGTGTGCGCTTCGACGTC
CACGACGTCACCCTGCACGCCGACGCCATCCACCGCGGAGGGGGCCAGATCATCCCCACA
GCACGGCGCTGCCTCTATGCCAGTGTGCTGACCGCCCAGCCACGCCTCATGGAGCCCATC
TACCTTGTGGAGATCCAGTGTCCAGAGCAGGTGGTCGGTGGCATCTACGGGGTTTTGAAC
AGGAAGCGGGGCCACGTGTTCGAGGAGTCCCAGGTGGCCGGCACCCCCATGTTTGTGGTC
AAGGCCTATCTGCCCGTCAACGAGTCCTTTGGCTTCACCGCTGACCTGAGGTCCAACACG
GGCGGCCAGGCGTTCCCCCAGTGTGTGTTTGACCACTGGCAGATCCTGCCCGGAGACCCC
TTCGACAACAGCAGCCGCCCCAGCCAGGTGGTGGCGGAGACCCGCAAGCGCAAGGGCCTG
AAAGAAGGCATCCCTGCCCTGGACAACTTCCTGGACAAATTGGTTTAAACGAATTCGAGC
TCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAA
CAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACC
CCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGG
TTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGC
TACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATT
CATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCA
GCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCG
CCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGG
ATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATG
CTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGC
TATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCG
CAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAG
GACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTC
GACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGAT
CTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGG
CGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATC
GAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAG
CATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGT
GAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGC
CGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATA
GCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTC
GTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGAC
GAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGT
ATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAA
GAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGC
GTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAG
GTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGT
GCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGG
AAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCG
CTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGG
TAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCAC
TGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTG
GCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGT
TACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGG
TGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCC
TTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTT
GGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGG
AACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGT
GGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAA
AATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCT
GCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAA
TCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGC
GTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAG
CGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCAT
GCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAG
AGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTC
GTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGG
ATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTG
CCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAA
CTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 2574 bp
Length: 2574 bp Restriction map B
Restriction map B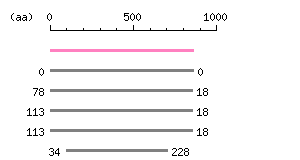
 more Linker info
more Linker info
{kind=link}