Nucleotide Sequence (with vector) for pF1KE0140
Download
>pF1KE0140 3968 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGAGGTGCCG
CCACCGGCACCGCGGAGCTTTCTCTGTAGAGCATTGTGCCTATTTCCCCGAGTCTTTGCT
GCCGAAGCTGTGACTGCCGATTCGGAAGTCCTTGAGGAGCGTCAGAAGCGGCTTCCCTAC
GTCCCAGAGCCCTATTACCCGGAATCTGGATGGGACCGCCTCCGGGAGCTGTTTGGCAAA
GATGAACAGCAGAGAATTTCAAAGGACCTTGCTAATATCTGTAAGACGGCGGCTACAGCA
GGCATCATTGGCTGGGTGTATGGGGGAATACCAGCTTTTATTCATGCTAAACAACAATAC
ATTGAGCAGAGCCAGGCAGAAATTTATCATAACCGGTTTGATGCTGTGCAATCTGCACAT
CGTGCTGCCACACGAGGCTTCATTCGTTATGGCTGGCGCTGGGGTTGGAGAACTGCAGTG
TTTGTGACTATATTCAACACAGTGAACACTAGTCTGAATGTATACCGAAATAAAGATGCC
TTAAGCCATTTTGTAATTGCAGGAGCTGTCACGGGAAGTCTTTTTAGGATAAACGTAGGC
CTGCGTGGCCTGGTGGCTGGTGGCATAATTGGAGCCTTGCTGGGCACTCCTGTAGGAGGC
CTGCTGATGGCATTTCAGAAGTACTCTGGTGAGACTGTTCAGGAAAGAAAACAGAAGGAT
CGAAAGGCACTCCATGAGCTAAAACTGGAAGAGTGGAAAGGCAGACTACAAGTTACTGAG
CACCTCCCTGAGAAAATTGAAAGTAGTTTACAGGAAGATGAACCTGAGAATGATGCTAAG
AAAATTGAAGCACTGCTAAACCTTCCTAGAAACCCTTCAGTAATAGATAAACAAGACAAG
GACGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCAT
GCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGC
TGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCT
GAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCG
CCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCA
GATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTA
CGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCA
AAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGG
ATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACA
GGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCT
TGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCC
GCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCC
GGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGC
GTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTG
GGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCC
ATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGAC
CACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGAT
CAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTC
AAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCG
AATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTG
GCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGC
GAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATC
GCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCG
ACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGA
ATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCG
TAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAA
AAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTT
TCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCT
GTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCT
CAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCC
CGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTT
ATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGC
TACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTAT
CTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAA
ACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAA
AAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGA
AAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCT
TTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACC
ATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTG
CATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTT
TGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTA
CAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACC
GCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACA
GATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGC
GGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAG
TGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTC
AGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTA
GGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGG
CAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATG
GCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTAT
CCGCTCAT



 Length: 855 bp
Length: 855 bp Restriction map B
Restriction map B
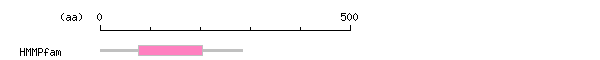
 more Linker info
more Linker info
{kind=link}