Nucleotide Sequence (with vector) for pF1KA1086
Download
>pF1KA1086 5810 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGACCCTGCC
GTGAACCCGGCCTTTCCCCCAGCTGCCCCGGCAGGGTACGGTGGATACCAGCCCCACTCC
GGCCAGGACTTCGCCTACGGCAGCCGACCCCAGGAGCCCGTCCCCACGGCCACCACCATG
GCTACCTACCAGGACAGTTACAGCTACGGACAGTCAGCAGCTGCCAGGAGCTATGAGGAC
AGGCCGTACTTCCAGTCTGCTGCCCTCCAGTCTGGGCGCATGACAGCCGCAGACTCCGGC
CAGCCAGGGACCCAAGAAGCCTGCGGGCAGCCCAGCCCCCATGGCAGTCACAGCCACGCT
CAGCCCCCACAGCAGGCGCCCATAGTGGAGTCCGGACAGCCAGCGAGCACCTTGTCCTCG
GGATACACCTACCCCACGGCGACAGGCGTCCAGCCCGAGTCGTCAGCTTCCATCATGACC
TCCTACCCCCCGCCCTCCTACAACCCCACCTGCACCGCCTACACGGCACCAAGCTACCCG
AACTATGACGCGTCGGTGTACTCCGCTGCCAGCCCTTTCTATCCTCCAGCGCAGCCCCCG
CCTCCCCCGGGACCCCCGCAGCAGCTGCCCCCGCCGCCCGCGCCTGCAGGCTCAGGAAGC
AGCCCCAGGGCCGACTCGAAGCCACCGCTTCCCAGCAAGCTGCCGAGACCCAAGGCGGGG
CCCAGGCAGCTCCAGCTTCACTACTGCGACATCTGCAAGATCAGCTGCGCTGGCCCCCAG
ACCTACCGGGAACATCTGGGAGGGCAGAAGCACAGAAAGAAGGAGGCGGCCCAGAAGACA
GGCGTGCAGCCCAACGGGAGCCCGCGCGGGGTGCAGGCGCAGCTGCATTGCGACCTGTGC
GCCGTGTCCTGCACCGGGGCGGACGCCTACGCGGCCCACATCCGGGGATCCAAGCACCAG
AAGGTCTTCAAGCTGCACGCCAAACTGGGGAAGCCCATTCCCACCCTCGAGCCTGCACTG
GCCACAGAGAGCCCCCCCGGGGCAGAGGCCAAGCCCACGTCCCCCACTGGCCCCAGCGTG
TGTGCCTCGAGCAGGCCAGCGCTGGCCAAGAGACCCGTGGCCTCGAAGGCCTTATGCGAG
GGGCCTCCTGAGCCACAGGCAGCAGGCTGCAGACCCCAGTGGGGGAAACCAGCCCAACCT
AAATTAGAGGGTCCCGGAGCACCTACCCAAGGAGGCTCAAAGGAAGCTCCCGCGGGCTGC
TCTGATGCGCAGCCGGTGGGCCCGGAATATGTGGAGGAGGTGTTCAGCGACGAAGGGCGA
GTGCTTCGCTTCCACTGCAAGCTGTGCGAGTGCAGTTTCAACGACCTTAACGCGAAGGAC
CTGCACGTGAGGGGGCGGCGGCACCGGCTGCAGTACCGGAAGAAAGTGAACCCGGACCTT
CCCATTGCCACGGAGCCCAGCAGCCGGGCTCGGAAGGTCCTGGAGGAGCGCATGAGGAAG
CAGCGGCACCTGGCGGAGGAGCGGCTGGAGCAGCTGCGGCGCTGGCACGCGGAGAGGAGG
CGGCTGGAGGAGGAGCCACCCCAGGACGTGCCGCCCCACGCGCCGCCCGACTGGGCCCAG
CCTCTGCTCATGGGCAGGCCGGAGTCACCCGCCAGCGCCCCACTCCAGCCCGGGCGGCGG
CCGGCGTCCAGCGACGACCGGCACGTCATGTGCAAGCACGCCACCATCTACCCCACGGAG
CAGGAGCTCCTGGCCGTGCAGAGGGCCGTGTCCCACGCAGAGCGGGCCCTCAAGCTGGTG
TCCGACACACTGGCCGAGGAGGACCGGGGCCGCCGAGAGGAAGAGGGTGACAAGCGCAGC
AGCGTTGCCCCCCAGACTCGGGTCCTGAAAGGCGTCATGCGAGTAGGCATCCTGGCGAAA
GGCCTCCTCCTGCGTGGGGACAGGAACGTGCGCCTCGCTCTGCTCTGCTCCGAGAAGCCC
ACGCACAGCCTGCTGCGGAGGATCGCCCAGCAGCTGCCCCGGCAGCTCCAGATGGTGACC
GAGGATGAGTATGAGGTCTCCTCCGACCCTGAAGCCAACATTGTCATCTCCTCCTGTGAG
GAGCCCAGGATGCAGGTCACCATATCTGTCACCTCACCTCTGATGCGGGAGGACCCCTCC
ACAGACCCAGGTGTGGAGGAGCCTCAGGCTGATGCAGGTGATGTCCTGAGCCCCAAGAAG
TGCCTCGAGTCCCTGGCCGCCCTCCGTCATGCCAGGTGGTTTCAGGCTCGAGCCAGCGGC
CTGCAGCCATGCGTGATCGTCATCAGGGTCCTGAGGGACCTCTGCCGGCGTGTGCCCACC
TGGGGGGCCCTGCCAGCCTGGGCCATGGAGCTGCTGGTGGAGAAGGCTGTGAGCAGTGCG
GCTGGGCCCCTGGGCCCCGGGGATGCAGTCAGGCGAGTCCTGGAGTGCGTGGCCACAGGG
ACGCTCCTGACAGACGGGCCCGGGCTCCAGGATCCCTGCGAGAGAGACCAGACAGATGCC
CTCGAGCCCATGACCCTCCAAGAGCGGGAAGACGTGACCGCCAGCGCCCAGCACGCCCTG
CGAATGCTGGCCTTCCGGCAGACCCACAAGGTCCTGGGCATGGATCTCCTGCCGCCCAGA
CACCGGCTGGGGGCCCGCTTCCGGAAGAGGCAACGGGGACCTGGCGAGGGAGAGGAGGGC
GCAGGGGAGAAGAAGCGGGGCCGGCGGGGCGGAGAGGGGCTCGTGGTTTAAACGAATTCG
AGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGC
TAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATA
ACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATC
CGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCA
AGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGAC
ATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTA
GCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGG
GCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCA
AGGATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGC
ATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTC
GGCTATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCA
GCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTG
CAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTG
CTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAG
GATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATG
CGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGC
ATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAA
GAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGAT
GGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAAT
GGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGAC
ATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTC
CTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTT
GACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACC
GGACTATAAAAGGATCTAGGTGAAGATCCTTTTTGATAATCTCATGACCAAAATCCCTTA
ACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTG
AAATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGC
GGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAG
CAGAGCGCAGATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAA
GAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGC
CAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGC
GCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTA
CACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAG
AAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCT
TCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGA
GCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGC
GGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTT
ATCCCCTGATTCTGTGGATAACCGTATTACCGCCTTTGAGTGAGCTGATACCGGAAATAC
AGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTC
AGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGT
TAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTG
TCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGT
AAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGA
TGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAG
AAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCC
CATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGC
GAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCT
TTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAG
CGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAA
CTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTAC
AAACTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 2697 bp
Length: 2697 bp Restriction map B
Restriction map B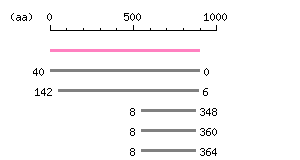
 more Linker info
more Linker info
{kind=link}