Nucleotide Sequence (with vector) for pF1KA1160
Download
>pF1KA1160 4106 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGGCCCGAAAT
GCAGAAAAGGCCATGACGGCCTTAGCAAGATTTCGCCAGGCTCAGCTGGAAGAGGGAAAA
GTGAAGGAACGAAGACCCTTTCTGGCCTCAGAATGTACTGAACTGCCTAAAGCTGAGAAG
TGGAGACGACAGATCATTGGAGAGATCTCTAAAAAAGTGGCTCAGATTCAGAATGCTGGT
TTAGGTGAATTTCGAATTCGTGACCTGAATGATGAAATTAACAAGCTGCTAAGGGAGAAA
GGACACTGGGAGGTCCGGATAAAGGAGCTGGGAGGTCCTGATTATGGAAAAGTTGGCCCT
AAAATGCTGGATCATGAAGGAAAAGAAGTCCCAGGAAACCGAGGTTACAAGTACTTTGGA
GCAGCAAAAGATTTGCCTGGTGTTAGAGAGCTGTTTGAAAAAGAACCTCTTCCTCCTCCC
AGAAAGACACGTGCTGAGCTCATGAAGGCAATCGATTTTGAGTACTATGGTTACCTAGAT
GAAGATGATGGTGTTATTGTGCCTTTGGAACAGGAATATGAAAAGAAACTCAGAGCCGAG
TTAGTGGAAAAGTGGAAAGCAGAGAGAGAGGCTCGGCTGGCAAGAGGAGAAAAGGAAGAG
GAGGAGGAAGAGGAGGAAGAGATCAACATCTATGCAGTCACCGAGGAGGAGTCGGACGAG
GAAGGCAGCCAGGAGAAAGGAGGGGACGACAGCCAGCAGAAGTTCATTGCTCACGTCCCT
GTTCCCTCGCAGCAAGAGATTGAGGAGGCACTGGTGCGAAGGAAGAAAATGGAACTCCTC
CAGAAGTATGCAAGCGAGACCCTGCAGGCCCAAAGTGAAGAAGCCAGAAGGCTCCTGGGC
TGCAGATCTGGGACACGGCCGGCCAGGAGCGGTTCCGCACCATCACCCAGAGCTACTACC
GCAGTGCCAATGGGGCCATCCTTGCCTACGACATCACCAAGAGGAGCTCCTTCCTGTCGG
TGCCTCACTGGATTGAGGATGGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTA
GAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGA
GTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGT
CTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAAC
CGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCT
TGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTT
CTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTT
GCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAG
CCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCA
AGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCAC
GCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACA
ATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTT
GTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCG
TGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGA
AGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCT
CCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCG
GCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATG
GAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCC
GAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCAT
GGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGAC
TGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATT
GCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCT
CCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTC
TGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGACTATAAAAGGATCTAGGTGAA
GATCCTTTTTGATAATCTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGC
GTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAAATCCTTTTTTTCTGCGCGTAAT
CTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGA
GCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGT
CCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATA
CCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTAC
CGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGG
TTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCG
TGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAG
CGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCT
TTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTC
AGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTT
TTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTTATCCCCTGATTCTGTGGATAACCG
TATTACCGCCTTTGAGTGAGCTGATACCGGAAATACAGGAACGCACGCTGGATGGCCCTT
CGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTG
GCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCG
GCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAAC
GCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCG
TAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGA
TCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTT
GCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACG
CCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATC
AAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGG
TGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAAC
GGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGA
AGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAA
ATACATTCAAATATGTATCCGCTCAT



 Length: 993 bp
Length: 993 bp Restriction map B
Restriction map B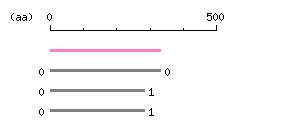
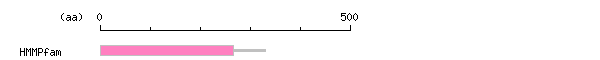
 more Linker info
more Linker info
{kind=link}