Nucleotide Sequence (with vector) for pF1KA0950
Download
>pF1KA0950 4061 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGACCCAGGGA
AAGCTCTCCGTGGCTAACAAGGCCCCTGGGACCGAGGGGCAGCAGCAGGTGCATGGCGAG
AAGAAGGAGGCTCCAGCAGTGCCCTCAGCCCCACCCTCCTATGAGGAAGCCACCTCTGGG
GAGGGGATGAAGGCAGGGGCCTTCCCCCCAGCCCCCACAGCGGTGCCTCTCCACCCTAGC
TGGGCCTATGTGGACCCCAGCAGCAGCTCCAGCTATGACAACGGTTTCCCCACCGGAGAC
CATGAGCTCTTCACCACTTTCAGCTGGGATGACCAGAAAGTTCGTCGAGTCTTTGTCAGA
AAGGTCTACACCATCCTGCTGATTCAGCTGCTGGTGACCTTGGCTGTCGTGGCTCTCTTT
ACTTTCTGTGACCCTGTCAAGGACTATGTCCAGGCCAACCCAGGCTGGTACTGGGCATCC
TATGCTGTGTTCTTTGCAACCTACCTGACCCTGGCTTGCTGTTCTGGACCCAGGAGGCAT
TTCCCCTGGAACCTGATTCTCCTGACCGTCTTTACCCTGTCCATGGCCTACCTCACTGGG
ATGCTGTCCAGCTACTACAACACCACCTCCGTGCTGCTGTGCCTGGGCATCACGGCCCTT
GTCTGCCTCTCAGTCACCGTCTTCAGCTTCCAGACCAAGTTCGACTTCACCTCCTGCCAG
GGCGTGCTCTTCGTGCTTCTCATGACTCTTTTCTTCAGCGGACTCATCCTGGCCATCCTC
CTACCCTTCCAATATGTGCCCTGGCTCCATGCAGTTTATGCAGCACTGGGAGCGGGTGTA
TTTACATTGTTCCTGGCACTTGACACCCAGTTGCTGATGGGTAACCGACGCCACTCGCTG
AGCCCTGAGGAGTATATTTTTGGAGCCCTCAACATTTACCTAGACATCATCTATATCTTC
ACCTTCTTCCTGCAGCTTTTTGGCACTAACCGAGAAGTTTAAACGAATTCGAGCTCGGTA
CCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGC
CCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGG
GGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCT
TGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTG
CTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCG
GGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTT
GCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCT
GGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGA
TGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAA
CAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGAC
TGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGG
CGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAG
GCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTT
GTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTG
TCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTG
CATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGA
GCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAG
GGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGAT
CTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTT
TCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTG
GCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTT
TACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTC
TTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGACTATAA
AAGGATCTAGGTGAAGATCCTTTTTGATAATCTCATGACCAAAATCCCTTAACGTGAGTT
TTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAAATCCTTT
TTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTG
TTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCA
GATACCAAATACTGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGT
AGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGA
TAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTC
GGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACT
GAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGA
CAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGG
AAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATT
TTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTT
ACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTTATCCCCTGA
TTCTGTGGATAACCGTATTACCGCCTTTGAGTGAGCTGATACCGGAAATACAGGAACGCA
CGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTA
AGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTA
TCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCC
GTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACT
TACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGG
CGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCT
GATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAA
CTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGG
GAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTA
TCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGA
ACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGC
ATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTT
TGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT



 Length: 948 bp
Length: 948 bp Restriction map B
Restriction map B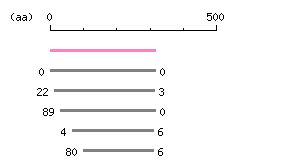

 more Linker info
more Linker info
{kind=link}