


-
SpecieshumanProduct IDFXC01630Cloning SiteSgfI-PmeISymbolPTGFRN
Alias : CD315, CD9P-1, EWI-F, FPRP, SMAP-6Descriptionprostaglandin F2 receptor inhibitor Length: 2637 bp
Length: 2637 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 879 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
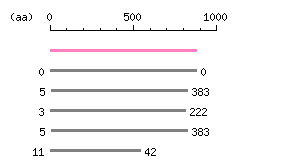
Entry Exp ID% symbol CCDS890.1 0 100.0 PTGFRN CCDS30813.1 1.5e-39 26.3 IGSF3 CCDS891.1 4.3e-36 25.6 CD101 CCDS30814.1 3.5e-32 25.6 IGSF3 CCDS1195.1 1.4e-23 30.0 IGSF8
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ]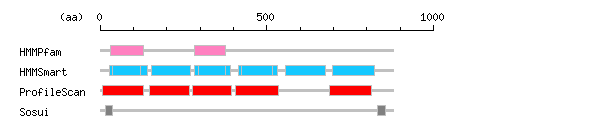 Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition HMMPfam IPR013106 30 130 PF07686 Immunoglobulin V-set IPR013106 283 376 PF07686 Immunoglobulin V-set HMMSmart IPR003599 28 141 SM00409 Immunoglobulin subtype IPR003596 38 121 SM00406 Immunoglobulin V-set IPR003599 154 270 SM00409 Immunoglobulin subtype IPR003599 284 390 SM00409 Immunoglobulin subtype IPR003596 294 375 SM00406 Immunoglobulin V-set IPR003599 414 532 SM00409 Immunoglobulin subtype IPR003596 424 517 SM00406 Immunoglobulin V-set IPR003599 556 676 SM00409 Immunoglobulin subtype IPR003599 696 822 SM00409 Immunoglobulin subtype ProfileScan IPR007110 8 129 PS50835 Immunoglobulin-like IPR007110 149 268 PS50835 Immunoglobulin-like IPR007110 276 394 PS50835 Immunoglobulin-like IPR007110 406 536 PS50835 Immunoglobulin-like IPR007110 688 813 PS50835 Immunoglobulin-like
Prediction of transmembrane (TM) segments
Method No. N terminal transmembrane region C terminal type length SOSUI2 1 15 SLALCRGRVVRVPTATLVRVVGT 37 SECONDARY 23 2 833 LLIGVGLSTVIGLLSCLIGYCSS 855 PRIMARY 23
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_065173 879 601204 100.0 100.0 XP_016857363 885 601204 100.0 98.2 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KSDA1436 Download>KIAA1436 2637 bp ATGGGGCGCCTGGCCTCGAGGCCGCTGCTGCTGGCGCTCCTGTCGTTGGCTCTTTGCCGA GGGCGTGTGGTGAGAGTCCCCACAGCGACCCTGGTTCGAGTGGTGGGCACTGAGCTGGTC ATCCCCTGCAACGTCAGTGACTATGATGGCCCCAGCGAGCAAAACTTTGACTGGAGCTTC TCATCTTTGGGGAGCAGCTTTGTGGAGCTTGCAAGCACCTGGGAGGTGGGGTTCCCAGCC CAGCTGTACCAGGAGCGGCTGCAGAGGGGCGAGATCCTGTTAAGGCGGACTGCCAACGAC GCCGTGGAGCTCCACATAAAGAACGTCCAGCCTTCAGACCAAGGCCACTACAAATGTTCA ACCCCCAGCACAGATGCCACTGTCCAGGGAAACTATGAGGACACAGTGCAGGTTAAAGTG CTGGCCGACTCCCTGCACGTGGGCCCCAGCGCGCGGCCCCCGCCGAGCCTGAGCCTGCGG GAGGGGGAGCCCTTCGAGCTGCGCTGCACTGCCGCCTCCGCCTCGCCGCTGCACACGCAC CTGGCGCTGCTGTGGGAGGTGCACCGCGGCCCGGCCAGGCGGAGCGTCCTCGCCCTGACC CACGAGGGCAGGTTCCACCCGGGCCTGGGGTACGAGCAGCGCTACCACAGTGGGGACGTG CGCCTCGACACCGTGGGCAGCGACGCCTACCGCCTCTCAGTGTCCCGGGCTCTGTCTGCC GACCAGGGCTCCTACAGGTGTATCGTCAGCGAGTGGATCGCCGAGCAGGGCAACTGGCAG GAAATCCAAGAAAAGGCCGTGGAAGTTGCCACCGTGGTGATCCAGCCATCAGTTCTGCGA GCAGCTGTGCCCAAGAATGTGTCTGTGGCTGAAGGAAAGGAACTGGACCTGACCTGTAAC ATCACAACAGACCGAGCCGATGACGTCCGGCCCGAGGTGACGTGGTCCTTCAGCAGGATG CCTGACAGCACCCTACCTGGCTCCCGCGTGTTGGCGCGGCTTGACCGTGATTCCCTGGTG CACAGCTCGCCTCATGTTGCTTTGAGTCATGTGGATGCACGCTCCTACCATTTACTGGTT CGGGATGTTAGCAAAGAAAACTCTGGCTACTATTACTGCCACGTGTCCCTGTGGGCACCC GGACACAACAGGAGCTGGCACAAAGTGGCAGAGGCCGTGTCTTCCCCAGCTGGTGTGGGT GTGACCTGGCTAGAACCAGACTACCAGGTGTACCTGAATGCTTCCAAGGTCCCCGGGTTT GCGGATGACCCCACAGAGCTGGCATGCCGGGTGGTGGACACGAAGAGTGGGGAGGCGAAT GTCCGATTCACGGTTTCGTGGTACTACAGGATGAACCGGCGCAGCGACAATGTGGTGACC AGCGAGCTGCTTGCAGTCATGGACGGGGACTGGACGCTAAAATATGGAGAGAGGAGCAAG CAGCGGGCCCAGGATGGAGACTTTATTTTTTCTAAGGAACATACAGACACGTTCAATTTC CGGATCCAAAGGACTACAGAGGAAGACAGAGGCAATTATTACTGTGTTGTGTCTGCCTGG ACCAAACAGCGGAACAACAGCTGGGTGAAAAGCAAGGATGTCTTCTCCAAGCCTGTTAAC ATATTTTGGGCATTAGAAGATTCCGTGCTTGTGGTGAAGGCGAGGCAGCCAAAGCCTTTC TTTGCTGCCGGAAATACATTTGAGATGACTTGCAAAGTATCTTCCAAGAATATTAAGTCG CCACGCTACTCTGTTCTCATCATGGCTGAGAAGCCTGTCGGCGACCTCTCCAGTCCCAAT GAAACGAAGTACATCATCTCTCTGGACCAGGATTCTGTGGTGAAGCTGGAGAATTGGACA GATGCATCACGGGTGGATGGCGTTGTTTTAGAAAAAGTGCAGGAGGATGAGTTCCGCTAT CGAATGTACCAGACTCAGGTCTCAGACGCAGGGCTGTACCGCTGCATGGTGACAGCCTGG TCTCCTGTCAGGGGCAGCCTTTGGCGAGAAGCAGCAACCAGTCTCTCCAATCCTATTGAG ATAGACTTCCAAACCTCAGGTCCTATATTTAATGCTTCTGTGCATTCAGACACACCATCA GTAATTCGGGGAGATCTGATCAAATTGTTCTGTATCATCACTGTCGAGGGAGCAGCACTG GATCCAGATGACATGGCCTTTGATGTGTCCTGGTTTGCGGTGCACTCTTTTGGCCTGGAC AAGGCTCCTGTGCTCCTGTCTTCCCTGGATCGGAAGGGCATCGTGACCACCTCCCGGAGG GACTGGAAGAGCGACCTCAGCCTGGAGCGCGTGAGTGTGCTGGAATTCTTGCTGCAAGTG CATGGCTCCGAGGACCAGGACTTTGGCAACTACTACTGTTCCGTGACTCCATGGGTGAAG TCACCAACAGGTTCCTGGCAGAAGGAGGCAGAGATCCACTCCAAGCCCGTTTTTATAACT GTGAAGATGGATGTGCTGAACGCCTTCAAGTATCCCTTGCTGATCGGCGTCGGTCTGTCC ACGGTCATCGGGCTCCTGTCCTGTCTCATCGGGTACTGCAGCTCCCACTGGTGTTGTAAG AAGGAGGTTCAGGAGACACGGCGCGAGCGCCGCAGGCTCATGTCGATGGAGATGGAC
Cloned ORF protein sequence for pF1KSDA1436 Download>KIAA1436 879 aa MGRLASRPLLLALLSLALCRGRVVRVPTATLVRVVGTELVIPCNVSDYDGPSEQNFDWSF SSLGSSFVELASTWEVGFPAQLYQERLQRGEILLRRTANDAVELHIKNVQPSDQGHYKCS TPSTDATVQGNYEDTVQVKVLADSLHVGPSARPPPSLSLREGEPFELRCTAASASPLHTH LALLWEVHRGPARRSVLALTHEGRFHPGLGYEQRYHSGDVRLDTVGSDAYRLSVSRALSA DQGSYRCIVSEWIAEQGNWQEIQEKAVEVATVVIQPSVLRAAVPKNVSVAEGKELDLTCN ITTDRADDVRPEVTWSFSRMPDSTLPGSRVLARLDRDSLVHSSPHVALSHVDARSYHLLV RDVSKENSGYYYCHVSLWAPGHNRSWHKVAEAVSSPAGVGVTWLEPDYQVYLNASKVPGF ADDPTELACRVVDTKSGEANVRFTVSWYYRMNRRSDNVVTSELLAVMDGDWTLKYGERSK QRAQDGDFIFSKEHTDTFNFRIQRTTEEDRGNYYCVVSAWTKQRNNSWVKSKDVFSKPVN IFWALEDSVLVVKARQPKPFFAAGNTFEMTCKVSSKNIKSPRYSVLIMAEKPVGDLSSPN ETKYIISLDQDSVVKLENWTDASRVDGVVLEKVQEDEFRYRMYQTQVSDAGLYRCMVTAW SPVRGSLWREAATSLSNPIEIDFQTSGPIFNASVHSDTPSVIRGDLIKLFCIITVEGAAL DPDDMAFDVSWFAVHSFGLDKAPVLLSSLDRKGIVTTSRRDWKSDLSLERVSVLEFLLQV HGSEDQDFGNYYCSVTPWVKSPTGSWQKEAEIHSKPVFITVKMDVLNAFKYPLLIGVGLS TVIGLLSCLIGYCSSHWCCKKEVQETRRERRRLMSMEMD
Nucleotide Sequence (with vector) for pF1KSDA1436 Download>pF1KSDA1436 5774 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT AGAACCATGGGGCGCCTGGCCTCGAGGCCGCTGCTGCTGGCGCTCCTGTCGTTGGCTCTT TGCCGAGGGCGTGTGGTGAGAGTCCCCACAGCGACCCTGGTTCGAGTGGTGGGCACTGAG CTGGTCATCCCCTGCAACGTCAGTGACTATGATGGCCCCAGCGAGCAAAACTTTGACTGG AGCTTCTCATCTTTGGGGAGCAGCTTTGTGGAGCTTGCAAGCACCTGGGAGGTGGGGTTC CCAGCCCAGCTGTACCAGGAGCGGCTGCAGAGGGGCGAGATCCTGTTAAGGCGGACTGCC AACGACGCCGTGGAGCTCCACATAAAGAACGTCCAGCCTTCAGACCAAGGCCACTACAAA TGTTCAACCCCCAGCACAGATGCCACTGTCCAGGGAAACTATGAGGACACAGTGCAGGTT AAAGTGCTGGCCGACTCCCTGCACGTGGGCCCCAGCGCGCGGCCCCCGCCGAGCCTGAGC CTGCGGGAGGGGGAGCCCTTCGAGCTGCGCTGCACTGCCGCCTCCGCCTCGCCGCTGCAC ACGCACCTGGCGCTGCTGTGGGAGGTGCACCGCGGCCCGGCCAGGCGGAGCGTCCTCGCC CTGACCCACGAGGGCAGGTTCCACCCGGGCCTGGGGTACGAGCAGCGCTACCACAGTGGG GACGTGCGCCTCGACACCGTGGGCAGCGACGCCTACCGCCTCTCAGTGTCCCGGGCTCTG TCTGCCGACCAGGGCTCCTACAGGTGTATCGTCAGCGAGTGGATCGCCGAGCAGGGCAAC TGGCAGGAAATCCAAGAAAAGGCCGTGGAAGTTGCCACCGTGGTGATCCAGCCATCAGTT CTGCGAGCAGCTGTGCCCAAGAATGTGTCTGTGGCTGAAGGAAAGGAACTGGACCTGACC TGTAACATCACAACAGACCGAGCCGATGACGTCCGGCCCGAGGTGACGTGGTCCTTCAGC AGGATGCCTGACAGCACCCTACCTGGCTCCCGCGTGTTGGCGCGGCTTGACCGTGATTCC CTGGTGCACAGCTCGCCTCATGTTGCTTTGAGTCATGTGGATGCACGCTCCTACCATTTA CTGGTTCGGGATGTTAGCAAAGAAAACTCTGGCTACTATTACTGCCACGTGTCCCTGTGG GCACCCGGACACAACAGGAGCTGGCACAAAGTGGCAGAGGCCGTGTCTTCCCCAGCTGGT GTGGGTGTGACCTGGCTAGAACCAGACTACCAGGTGTACCTGAATGCTTCCAAGGTCCCC GGGTTTGCGGATGACCCCACAGAGCTGGCATGCCGGGTGGTGGACACGAAGAGTGGGGAG GCGAATGTCCGATTCACGGTTTCGTGGTACTACAGGATGAACCGGCGCAGCGACAATGTG GTGACCAGCGAGCTGCTTGCAGTCATGGACGGGGACTGGACGCTAAAATATGGAGAGAGG AGCAAGCAGCGGGCCCAGGATGGAGACTTTATTTTTTCTAAGGAACATACAGACACGTTC AATTTCCGGATCCAAAGGACTACAGAGGAAGACAGAGGCAATTATTACTGTGTTGTGTCT GCCTGGACCAAACAGCGGAACAACAGCTGGGTGAAAAGCAAGGATGTCTTCTCCAAGCCT GTTAACATATTTTGGGCATTAGAAGATTCCGTGCTTGTGGTGAAGGCGAGGCAGCCAAAG CCTTTCTTTGCTGCCGGAAATACATTTGAGATGACTTGCAAAGTATCTTCCAAGAATATT AAGTCGCCACGCTACTCTGTTCTCATCATGGCTGAGAAGCCTGTCGGCGACCTCTCCAGT CCCAATGAAACGAAGTACATCATCTCTCTGGACCAGGATTCTGTGGTGAAGCTGGAGAAT TGGACAGATGCATCACGGGTGGATGGCGTTGTTTTAGAAAAAGTGCAGGAGGATGAGTTC CGCTATCGAATGTACCAGACTCAGGTCTCAGACGCAGGGCTGTACCGCTGCATGGTGACA GCCTGGTCTCCTGTCAGGGGCAGCCTTTGGCGAGAAGCAGCAACCAGTCTCTCCAATCCT ATTGAGATAGACTTCCAAACCTCAGGTCCTATATTTAATGCTTCTGTGCATTCAGACACA CCATCAGTAATTCGGGGAGATCTGATCAAATTGTTCTGTATCATCACTGTCGAGGGAGCA GCACTGGATCCAGATGACATGGCCTTTGATGTGTCCTGGTTTGCGGTGCACTCTTTTGGC CTGGACAAGGCTCCTGTGCTCCTGTCTTCCCTGGATCGGAAGGGCATCGTGACCACCTCC CGGAGGGACTGGAAGAGCGACCTCAGCCTGGAGCGCGTGAGTGTGCTGGAATTCTTGCTG CAAGTGCATGGCTCCGAGGACCAGGACTTTGGCAACTACTACTGTTCCGTGACTCCATGG GTGAAGTCACCAACAGGTTCCTGGCAGAAGGAGGCAGAGATCCACTCCAAGCCCGTTTTT ATAACTGTGAAGATGGATGTGCTGAACGCCTTCAAGTATCCCTTGCTGATCGGCGTCGGT CTGTCCACGGTCATCGGGCTCCTGTCCTGTCTCATCGGGTACTGCAGCTCCCACTGGTGT TGTAAGAAGGAGGTTCAGGAGACACGGCGCGAGCGCCGCAGGCTCATGTCGATGGAGATG GACTACGTAGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGC AGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGC CACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTT TTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAAAACCGCCCAGTCTAG CTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCT TGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCGTTTCTGCGGACTGGC TTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGA GCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTA AACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGATCAAGATCTGATCAA GAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTGCACGCAGGTTCTCCG GCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAGACAATCGGCTGCTCT GATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTTTTTGTCAAGACCGAC CTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTATCGTGGCTGGCCACG ACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCGGGAAGGGACTGGCTG CTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTTGCTCCTGCCGAGAAA GTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGATCCGGCTACCTGCCCA TTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGGATGGAAGCCGGTCTT GTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCAGCCGAACTGTTCGCC AGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACTCATGGCGATGCCTGC TTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATCGACTGTGGCCGGCTG GGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGATATTGCTGAAGAGCTT GGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCCGCTCCCGATTCGCAG CGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAA TGACCGACCAAGCGACGCCCAACCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATC CACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAG GAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCA TCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCA GGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGG ATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAG GTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGT TCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACA CGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGG CGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATT TGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATC CGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCG CAGAAAAAAAGGATTTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTG GAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTA GATCCTTTTATAGTCCGGAAATACAGGAACGCACGCTGGATGGCCCTTCGCTGGGATGGT GAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAATGTGGCCTGTACCCTC TGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATTGCGGCAGTTTTTCGG GTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTGAACGCGTTTTAGCGG TGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCCTCGTAGCCATCGAGA TAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCGAGATCTTTTCAGCCT GATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAATTTGCCTGGCGGCAG TAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAAACGCCGTAGCGCCGA TGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGCATCAAATAAAACGAA AGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGTCGGTGAACGCTCTCC TGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGCAACGGCCCGGAGGGT GGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGCAGAAGGCCATCCTGA CGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTCTAAATACATTCAAAT ATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}