


-
SpecieshumanProduct IDFXC00831Cloning SiteSgfI-PmeISymbolZFP28
Alias : mkr5DescriptionZFP28 zinc finger protein, transcript variant 1 Length: 2604 bp
Length: 2604 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 868 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
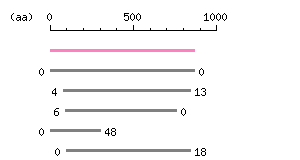
Entry Exp ID% symbol CCDS12946.1 1.9e-193 99.9 ZFP28 CCDS33122.1 6.4e-65 55.2 ZNF470 CCDS12945.1 1.8e-64 57.3 ZNF471 CCDS77363.1 4.9e-62 99.7 ZFP28 CCDS12498.1 3.7e-60 45.7 ZNF420
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition HMMPfam IPR001909 103 143 PF01352 Krueppel-associated box IPR001909 232 268 PF01352 Krueppel-associated box IPR007087 420 442 PF00096 Zinc finger IPR007087 561 583 PF00096 Zinc finger IPR007087 589 611 PF00096 Zinc finger IPR007087 617 639 PF00096 Zinc finger IPR007087 645 667 PF00096 Zinc finger IPR007087 673 695 PF00096 Zinc finger IPR007087 757 779 PF00096 Zinc finger HMMSmart IPR001909 103 163 SM00349 Krueppel-associated box IPR001909 232 288 SM00349 Krueppel-associated box IPR015880 420 442 SM00355 Zinc finger IPR015880 448 470 SM00355 Zinc finger IPR015880 476 499 SM00355 Zinc finger IPR015880 505 527 SM00355 Zinc finger IPR015880 533 555 SM00355 Zinc finger IPR015880 561 583 SM00355 Zinc finger IPR015880 589 611 SM00355 Zinc finger IPR015880 617 639 SM00355 Zinc finger IPR015880 645 667 SM00355 Zinc finger IPR015880 673 695 SM00355 Zinc finger IPR015880 701 723 SM00355 Zinc finger IPR015880 729 751 SM00355 Zinc finger IPR015880 757 779 SM00355 Zinc finger IPR015880 785 807 SM00355 Zinc finger ProfileScan IPR001909 103 174 PS50805 Krueppel-associated box IPR001909 232 299 PS50805 Krueppel-associated box IPR007087 420 447 PS50157 Zinc finger IPR007087 448 475 PS50157 Zinc finger IPR007087 476 504 PS50157 Zinc finger IPR007087 505 532 PS50157 Zinc finger IPR007087 533 560 PS50157 Zinc finger IPR007087 561 588 PS50157 Zinc finger IPR007087 589 616 PS50157 Zinc finger IPR007087 617 644 PS50157 Zinc finger IPR007087 645 672 PS50157 Zinc finger IPR007087 673 700 PS50157 Zinc finger IPR007087 701 728 PS50157 Zinc finger IPR007087 729 756 PS50157 Zinc finger IPR007087 757 784 PS50157 Zinc finger IPR007087 785 812 PS50157 Zinc finger IPR007087 813 840 PS50157 Zinc finger
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_065879 868 616798 99.9 100.0 XP_011524765 859 616798 97.6 94.8 XP_011524764 771 616798 99.9 88.8 NP_003405 743 604752 42.9 85.0 NP_001309068 782 600398 44.4 81.5 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KSDA1431 Download>KIAA1431 2604 bp ATGCGGGGGGCGGCGAGCGCGAGTGTCCGCGAGCCGACGCCGCTCCCGGGTAGAGGCGCC CCCCGCACAAAGCCCCGGGCGGGCCGAGGCCCGACTGTAGGGACTCCAGCCACCTTGGCC CTCCCTGCCCGGGGAAGGCCGCGCTCAAGGAATGGCCTCGCATCCAAAGGCCAGCGAGGA GCGGCCCCTACGGGGCCTGGGCACAGAGCTCTGCCTTCCAGGGACACTGCTCTTCCCCAG GAGAGAAACAAGAAGCTGGAGGCTGTGGGGACAGGAATTGAACCTAAAGCCATGTCCCAG GGCTTGGTGACATTTGGGGATGTGGCTGTAGATTTCTCCCAAGAGGAGTGGGAGTGGCTG AACCCCATTCAGAGGAACTTGTACAGGAAGGTGATGTTGGAGAACTACAGGAACCTGGCA TCGCTGGGACTTTGTGTTTCTAAGCCCGATGTGATCTCCTCGTTGGAACAAGGAAAAGAG CCTTGGACAGTGAAGCGAAAGATGACAAGAGCCTGGTGCCCAGACTTGAAGGCTGTGTGG AAGATCAAGGAGTTACCTCTCAAGAAGGACTTCTGCGAAGGAAAGCTATCCCAGGCAGTG ATAACAGAGAGACTCACAAGCTATAATCTGGAGTACTCTCTGTTAGGGGAACACTGGGAT TATGATGCTCTGTTTGAGACACAGCCGGGCTTGGTGACTATCAAAAACCTGGCTGTTGAC TTCCGCCAGCAGCTACACCCAGCTCAGAAGAATTTCTGTAAGAATGGGATATGGGAGAAC AACAGTGACCTGGGATCAGCAGGACATTGTGTGGCTAAGCCAGATTTAGTCTCTTTACTA GAGCAAGAGAAGGAGCCCTGGATGGTGAAGCGAGAGCTGACAGGAAGCCTGTTCTCAGGC CAGCGATCTGTACATGAGACCCAGGAATTATTTCCAAAGCAAGATTCATATGCTGAAGGG GTAACAGACAGAACCTCAAACACTAAACTTGATTGTTCCAGTTTCAGAGAAAATTGGGAT TCTGACTATGTGTTCGGAAGGAAGCTTGCAGTAGGTCAAGAGACACAATTCAGGCAAGAG CCAATTACTCATAACAAAACCCTCTCTAAGGAAAGAGAACGTACATATAACAAATCTGGA AGATGGTCCTATTTGGACGATTCAGAAGAGAAAGTTCATAATCGTGATTCAATTAAAAAT TTTCAAAAAAGTTCAGTGGTAATAAAACAAACAGGCATCTATGCAGGAAAAAAGCTTTTC AAGTGTAATGAATGTAAGAAAACTTTTACCCAGAGCTCATCTCTTACTGTTCATCAGAGA ATTCACACTGGAGAGAAACCTTATAAATGTAATGAATGTGGGAAGGCCTTTAGTGACGGC TCATCCTTTGCCCGACACCAGAGATGTCACACTGGCAAGAAGCCCTATGAGTGCATTGAG TGTGGGAAAGCTTTCATACAGAACACATCCCTTATCCGTCACTGGAGATACTATCATACT GGGGAGAAACCCTTTGATTGCATCGATTGTGGGAAAGCCTTCAGTGACCACATAGGGCTT AATCAACACAGGAGAATTCATACTGGAGAGAAACCTTACAAATGTGATGTATGTCACAAA TCCTTCAGGTATGGTTCCTCCCTTACTGTACATCAAAGGATTCATACCGGAGAAAAACCA TATGAATGTGATGTTTGCAGAAAAGCCTTCAGCCATCATGCATCACTCACTCAACATCAA AGAGTACATTCTGGAGAAAAGCCTTTTAAGTGTAAAGAGTGCGGAAAAGCTTTTAGGCAG AATATACACCTTGCCAGTCATTTAAGGATTCATACTGGGGAGAAGCCTTTTGAATGTGCG GAGTGTGGAAAATCCTTCAGCATCAGTTCTCAGCTTGCCACTCATCAGAGAATCCATACT GGAGAGAAGCCCTATGAATGTAAGGTTTGTAGTAAAGCGTTCACCCAGAAGGCTCACCTT GCACAGCATCAGAAAACCCATACAGGAGAGAAACCATATGAGTGCAAGGAATGCGGTAAA GCCTTCAGCCAGACCACACACCTCATTCAACATCAGAGAGTTCACACTGGTGAGAAACCC TATAAATGTATGGAATGTGGGAAGGCCTTTGGTGATAACTCATCCTGTACTCAACATCAA AGACTGCACACTGGCCAAAGACCTTATGAATGTATTGAGTGTGGAAAGGCATTCAAGACA AAATCCTCCCTTATTTGTCATCGCAGAAGTCATACTGGAGAAAAACCTTATGAATGCAGT GTGTGTGGCAAAGCCTTTAGTCATCGTCAATCCCTTAGTGTACATCAGAGAATCCATTCT GGAAAGAAACCATATGAATGTAAGGAATGTAGGAAAACCTTCATCCAAATTGGACACCTT AATCAACATAAGAGAGTTCATACTGGAGAGAGATCTTATAACTATAAGAAAAGCAGAAAA GTCTTCAGGCAAACTGCTCACTTAGCTCATCATCAGCGAATTCATACTGGAGAGTCGTCA ACATGCCCCTCTTTACCTTCCACGTCAAATCCTGTGGATCTGTTTCCCAAATTTCTCTGG AATCCATCCTCCCTCCCATCACCA
Cloned ORF protein sequence for pF1KSDA1431 Download>KIAA1431 868 aa MRGAASASVREPTPLPGRGAPRTKPRAGRGPTVGTPATLALPARGRPRSRNGLASKGQRG AAPTGPGHRALPSRDTALPQERNKKLEAVGTGIEPKAMSQGLVTFGDVAVDFSQEEWEWL NPIQRNLYRKVMLENYRNLASLGLCVSKPDVISSLEQGKEPWTVKRKMTRAWCPDLKAVW KIKELPLKKDFCEGKLSQAVITERLTSYNLEYSLLGEHWDYDALFETQPGLVTIKNLAVD FRQQLHPAQKNFCKNGIWENNSDLGSAGHCVAKPDLVSLLEQEKEPWMVKRELTGSLFSG QRSVHETQELFPKQDSYAEGVTDRTSNTKLDCSSFRENWDSDYVFGRKLAVGQETQFRQE PITHNKTLSKERERTYNKSGRWSYLDDSEEKVHNRDSIKNFQKSSVVIKQTGIYAGKKLF KCNECKKTFTQSSSLTVHQRIHTGEKPYKCNECGKAFSDGSSFARHQRCHTGKKPYECIE CGKAFIQNTSLIRHWRYYHTGEKPFDCIDCGKAFSDHIGLNQHRRIHTGEKPYKCDVCHK SFRYGSSLTVHQRIHTGEKPYECDVCRKAFSHHASLTQHQRVHSGEKPFKCKECGKAFRQ NIHLASHLRIHTGEKPFECAECGKSFSISSQLATHQRIHTGEKPYECKVCSKAFTQKAHL AQHQKTHTGEKPYECKECGKAFSQTTHLIQHQRVHTGEKPYKCMECGKAFGDNSSCTQHQ RLHTGQRPYECIECGKAFKTKSSLICHRRSHTGEKPYECSVCGKAFSHRQSLSVHQRIHS GKKPYECKECRKTFIQIGHLNQHKRVHTGERSYNYKKSRKVFRQTAHLAHHQRIHTGESS TCPSLPSTSNPVDLFPKFLWNPSSLPSP
Nucleotide Sequence (with vector) for pF1KSDA1431 Download>pF1KSDA1431 5741 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT AGAACCATGCGGGGGGCGGCGAGCGCGAGTGTCCGCGAGCCGACGCCGCTCCCGGGTAGA GGCGCCCCCCGCACAAAGCCCCGGGCGGGCCGAGGCCCGACTGTAGGGACTCCAGCCACC TTGGCCCTCCCTGCCCGGGGAAGGCCGCGCTCAAGGAATGGCCTCGCATCCAAAGGCCAG CGAGGAGCGGCCCCTACGGGGCCTGGGCACAGAGCTCTGCCTTCCAGGGACACTGCTCTT CCCCAGGAGAGAAACAAGAAGCTGGAGGCTGTGGGGACAGGAATTGAACCTAAAGCCATG TCCCAGGGCTTGGTGACATTTGGGGATGTGGCTGTAGATTTCTCCCAAGAGGAGTGGGAG TGGCTGAACCCCATTCAGAGGAACTTGTACAGGAAGGTGATGTTGGAGAACTACAGGAAC CTGGCATCGCTGGGACTTTGTGTTTCTAAGCCCGATGTGATCTCCTCGTTGGAACAAGGA AAAGAGCCTTGGACAGTGAAGCGAAAGATGACAAGAGCCTGGTGCCCAGACTTGAAGGCT GTGTGGAAGATCAAGGAGTTACCTCTCAAGAAGGACTTCTGCGAAGGAAAGCTATCCCAG GCAGTGATAACAGAGAGACTCACAAGCTATAATCTGGAGTACTCTCTGTTAGGGGAACAC TGGGATTATGATGCTCTGTTTGAGACACAGCCGGGCTTGGTGACTATCAAAAACCTGGCT GTTGACTTCCGCCAGCAGCTACACCCAGCTCAGAAGAATTTCTGTAAGAATGGGATATGG GAGAACAACAGTGACCTGGGATCAGCAGGACATTGTGTGGCTAAGCCAGATTTAGTCTCT TTACTAGAGCAAGAGAAGGAGCCCTGGATGGTGAAGCGAGAGCTGACAGGAAGCCTGTTC TCAGGCCAGCGATCTGTACATGAGACCCAGGAATTATTTCCAAAGCAAGATTCATATGCT GAAGGGGTAACAGACAGAACCTCAAACACTAAACTTGATTGTTCCAGTTTCAGAGAAAAT TGGGATTCTGACTATGTGTTCGGAAGGAAGCTTGCAGTAGGTCAAGAGACACAATTCAGG CAAGAGCCAATTACTCATAACAAAACCCTCTCTAAGGAAAGAGAACGTACATATAACAAA TCTGGAAGATGGTCCTATTTGGACGATTCAGAAGAGAAAGTTCATAATCGTGATTCAATT AAAAATTTTCAAAAAAGTTCAGTGGTAATAAAACAAACAGGCATCTATGCAGGAAAAAAG CTTTTCAAGTGTAATGAATGTAAGAAAACTTTTACCCAGAGCTCATCTCTTACTGTTCAT CAGAGAATTCACACTGGAGAGAAACCTTATAAATGTAATGAATGTGGGAAGGCCTTTAGT GACGGCTCATCCTTTGCCCGACACCAGAGATGTCACACTGGCAAGAAGCCCTATGAGTGC ATTGAGTGTGGGAAAGCTTTCATACAGAACACATCCCTTATCCGTCACTGGAGATACTAT CATACTGGGGAGAAACCCTTTGATTGCATCGATTGTGGGAAAGCCTTCAGTGACCACATA GGGCTTAATCAACACAGGAGAATTCATACTGGAGAGAAACCTTACAAATGTGATGTATGT CACAAATCCTTCAGGTATGGTTCCTCCCTTACTGTACATCAAAGGATTCATACCGGAGAA AAACCATATGAATGTGATGTTTGCAGAAAAGCCTTCAGCCATCATGCATCACTCACTCAA CATCAAAGAGTACATTCTGGAGAAAAGCCTTTTAAGTGTAAAGAGTGCGGAAAAGCTTTT AGGCAGAATATACACCTTGCCAGTCATTTAAGGATTCATACTGGGGAGAAGCCTTTTGAA TGTGCGGAGTGTGGAAAATCCTTCAGCATCAGTTCTCAGCTTGCCACTCATCAGAGAATC CATACTGGAGAGAAGCCCTATGAATGTAAGGTTTGTAGTAAAGCGTTCACCCAGAAGGCT CACCTTGCACAGCATCAGAAAACCCATACAGGAGAGAAACCATATGAGTGCAAGGAATGC GGTAAAGCCTTCAGCCAGACCACACACCTCATTCAACATCAGAGAGTTCACACTGGTGAG AAACCCTATAAATGTATGGAATGTGGGAAGGCCTTTGGTGATAACTCATCCTGTACTCAA CATCAAAGACTGCACACTGGCCAAAGACCTTATGAATGTATTGAGTGTGGAAAGGCATTC AAGACAAAATCCTCCCTTATTTGTCATCGCAGAAGTCATACTGGAGAAAAACCTTATGAA TGCAGTGTGTGTGGCAAAGCCTTTAGTCATCGTCAATCCCTTAGTGTACATCAGAGAATC CATTCTGGAAAGAAACCATATGAATGTAAGGAATGTAGGAAAACCTTCATCCAAATTGGA CACCTTAATCAACATAAGAGAGTTCATACTGGAGAGAGATCTTATAACTATAAGAAAAGC AGAAAAGTCTTCAGGCAAACTGCTCACTTAGCTCATCATCAGCGAATTCATACTGGAGAG TCGTCAACATGCCCCTCTTTACCTTCCACGTCAAATCCTGTGGATCTGTTTCCCAAATTT CTCTGGAATCCATCCTCCCTCCCATCACCATACGTAGTTTAAACGAATTCGAGCTCGGTA CCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGC CCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGG GGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCT TGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTG CTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCG GGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTT GCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCT GGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGA TGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAA CAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGAC TGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGG CGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAG GCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTT GTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTG TCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTG CATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGA GCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAG GGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGAT CTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTT TCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTG GCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTT TACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTC TTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGTATCAGC TCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACAT GTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTT CCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCG AAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTC TCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGT GGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAA GCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTA TCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAA CAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAA CTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTT CGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTT TTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCCTTTGAT CTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCAT GAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGGAACGCA CGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTA AGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTA TCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCC GTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACT TACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGG CGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCT GATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAA CTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGG GAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTA TCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGA ACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGC ATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTT TGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}