Nucleotide Sequence (with vector) for pF1KE0100
Download
>pF1KE0100 5609 bp
GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA
TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCCATGTCCGAGGCT
GGCGGGGCCGGGCCGGGCGGCTGCGGGGCAGGAGCCGGGGCAGGGGCCGGGCCCGGGGCG
CTGCCCCCGCAGCCTGCGGCGCTTCCGCCCGCGCCCCCGCAGGGCTCCCCCTGCGCCGCT
GCCGCCGGGGGCTCGGGCGCCTGCGGTCCGGCGACGGCAGTGGCTGCAGCGGGCACGGCC
GAAGGACCGGGAGGCGGTGGCTCGGCCCGAATCGCCGTGAAGAAAGCGCAACTACGCTCC
GCTCCGCGGGCCAAGAAACTGGAGAAACTCGGAGTGTACTCCGCCTGCAAGGCCGAGGAG
TCTTGTAAATGTAATGGCTGGAAAAACCCTAACCCCTCACCCACTCCCCCCAGAGCCGAC
CTGCAGCAAATAATTGTCAGTCTAACAGAATCCTGTCGGAGTTGTAGCCATGCCCTAGCT
GCTCATGTTTCCCACCTGGAGAATGTGTCAGAGGAAGAAATGAACAGACTCCTGGGAATA
GTATTGGATGTGGAATATCTCTTTACCTGTGTCCACAAGGAAGAAGATGCAGATACCAAA
CAAGTTTATTTCTATCTATTTAAGCTCTTGAGAAAGTCTATTTTACAAAGAGGAAAACCT
GTGGTTGAAGGCTCTTTGGAAAAGAAACCCCCATTTGAAAAACCTAGCATTGAACAGGGT
GTGAATAACTTTGTGCAGTACAAATTTAGTCACCTGCCAGCAAAAGAAAGGCAAACAATA
GTTGAGTTGGCAAAAATGTTCCTAAACCGCATCAACTATTGGCATCTGGAGGCACCATCT
CAACGAAGACTGCGATCTCCCAATGATGATATTTCTGGATACAAAGAGAACTACACAAGG
TGGCTGTGTTACTGCAACGTGCCACAGTTCTGCGACAGTCTACCTCGGTACGAAACCACA
CAGGTGTTTGGGAGAACATTGCTTCGCTCGGTCTTCACTGTTATGAGGCGACAACTCCTG
GAACAAGCAAGACAGGAAAAAGATAAACTGCCTCTTGAAAAACGAACTCTAATCCTCACT
CATTTCCCAAAATTTCTGTCCATGCTAGAAGAAGAAGTATATAGTCAAAACTCTCCCATC
TGGGATCAGGATTTTCTCTCAGCCTCTTCCAGAACCAGCCAGCTAGGCATCCAAACAGTT
ATCAATCCACCTCCTGTGGCTGGGACAATTTCATACAATTCAACCTCATCTTCCCTTGAG
CAGCCAAACGCAGGGAGCAGCAGTCCTGCCTGCAAAGCCTCTTCTGGACTTGAGGCAAAC
CCAGGAGAAAAGAGGAAAATGACTGATTCTCATGTTCTGGAGGAGGCCAAGAAACCCCGA
GTTATGGGGGATATTCCGATGGAATTAATCAACGAGGTTATGTCTACCATCACGGACCCT
GCAGCAATGCTTGGACCAGAGACCAATTTTCTGTCAGCACACTCGGCCAGGGATGAGGCG
GCAAGGTTGGAAGAGCGCAGGGGTGTAATTGAATTTCACGTGGTTGGCAATTCCCTCAAC
CAGAAACCAAACAAGAAGATCCTGATGTGGCTGGTTGGCCTACAGAACGTTTTCTCCCAC
CAGCTGCCCCGAATGCCAAAAGAATACATCACACGGCTCGTCTTTGACCCGAAACACAAA
ACCCTTGCTTTAATTAAAGATGGCCGTGTTATTGGTGGTATCTGTTTCCGTATGTTCCCA
TCTCAAGGATTCACAGAGATTGTCTTCTGTGCTGTAACCTCAAATGAGCAAGTCAAGGGC
TATGGAACACACCTGATGAATCATTTGAAAGAATATCACATAAAGCATGACATCCTGAAC
TTCCTCACATATGCAGATGAATATGCAATTGGATACTTTAAGAAACAGGGTTTCTCCAAA
GAAATTAAAATACCTAAAACCAAATATGTTGGCTATATCAAGGATTATGAAGGAGCCACT
TTAATGGGATGTGAGCTAAATCCACGGATCCCGTACACAGAATTTTCTGTCATCATTAAA
AAGCAGAAGGAGATAATTAAAAAACTGATTGAAAGAAAACAGGCACAAATTCGAAAAGTT
TACCCTGGACTTTCATGTTTTAAAGATGGAGTTCGACAGATTCCTATAGAAAGCATTCCT
GGAATTAGAGAGACAGGCTGGAAACCGAGTGGAAAAGAGAAAAGTAAAGAGCCCAGAGAC
CCTGACCAGCTTTACAGCACGCTCAAGAGCATCCTCCAGCAGGTGAAGAGCCATCAAAGC
GCTTGGCCCTTCATGGAACCTGTGAAGAGAACAGAAGCTCCAGGATATTATGAAGTTATA
AGGTTCCCCATGGATCTGAAAACCATGAGTGAACGCCTCAAGAATAGGTACTACGTGTCT
AAGAAATTATTCATGGCAGACTTACAGCGAGTCTTTACCAATTGCAAAGAGTACAACCCC
CCTGAGAGTGAATACTACAAATGTGCCAATATCCTGGAGAAATTCTTCTTCAGTAAAATT
AAGGAAGCTGGATTAATTGACAAGGTTTAAACGAATTCGAGCTCGGTACCCGGGGATCCT
CTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAACAAAGCCCGAAAGGAAGC
TGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACG
GGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGGTTCGCTTGCTGTCCATAA
AACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGCTACCTGCTTTCTCTTTGC
GCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATTCATCCGGGGTCAGCACCG
TTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCAGCCCTTGCGCCCTGAGTG
CTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCGCCCTCTGGTAAGGTTGGG
AAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGGATCTGATGGCGCAGGGGA
TCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATGCTTGAACAAGATGGATTG
CACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGCTATGACTGGGCACAACAG
ACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCGCAGGGGCGCCCGGTTCTT
TTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAGGACGAGGCAGCGCGGCTA
TCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTCGACGTTGTCACTGAAGCG
GGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGATCTCCTGTCATCTCACCTT
GCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGGCGGCTGCATACGCTTGAT
CCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATCGAGCGAGCACGCACTCGG
ATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAGCATCAGGGGCTCGCGCCA
GCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGTGAGGATCTCGTCGTGACT
CATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGCCGCTTTTCTGGATTCATC
GACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATAGCGTTGGCTACCCGTGAT
ATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTCGTGCTTTACGGTATCGCC
GCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGACGAGTTCTTCTGAGCGGGA
CTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGACTATAAAAGGATCTAGGT
GAAGATCCTTTTTGATAATCTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTG
AGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAAATCCTTTTTTTCTGCGCGT
AATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCA
AGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATAC
TGTCCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTAC
ATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCT
TACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGG
GGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACA
GCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGT
AAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTA
TCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTC
GTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGC
CTTTTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTTATCCCCTGATTCTGTGGATAA
CCGTATTACCGCCTTTGAGTGAGCTGATACCGGAAATACAGGAACGCACGCTGGATGGCC
CTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGTGGATTAAGTGGGGGTAAT
GTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAAAATTTATCAGGCGCGATT
GCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCTGCTGCCGTGATCGCGCTG
AACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAATCCACTTACTGTCTGCCC
TCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGCGTCCGGCGTAGAGGATCG
AGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAGCGGTCTGATAAAACAGAA
TTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCATGCCGAACTCAGAAGTGAA
ACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAGAGTAGGGAACTGCCAGGC
ATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTCGTTTTATCTGTTGTTTGT
CGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGGATTTGAACGTTGCGAAGC
AACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTGCCAGGCATCAAATTAAGC
AGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAACTCTTTTGTTTATTTTTC
TAAATACATTCAAATATGTATCCGCTCAT



 Length: 2496 bp
Length: 2496 bp Restriction map B
Restriction map B
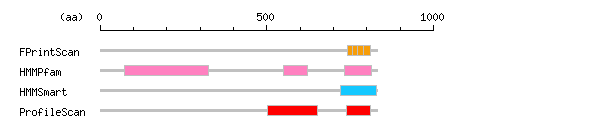
 more Linker info
more Linker info
{kind=link}