


-
SpecieshumanProduct IDFXC00392Cloning SiteSgfI-PmeISymbolZNF33A
Alias : KOX2, KOX31, KOX5, NF11A, ZNF11, ZNF11A, ZNF33, ZZAPKDescriptionzinc finger protein 33A, transcript variant 2 Length: 2430 bp
Length: 2430 bp
Restriction map A
 Restriction map B
Restriction map B
Genomic Structure
-
Length: 810 aa
Result of homology search against CCDS protein database (
FASTA output,
Multiple alignment)
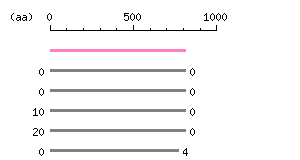
Entry Exp ID% symbol CCDS31182.1 6e-182 100.0 ZNF33A CCDS44372.1 1.5e-181 99.9 ZNF33A CCDS60514.1 2.6e-181 100.0 ZNF33A CCDS73088.1 6.1e-181 99.8 ZNF33A CCDS7198.1 1.3e-160 92.8 ZNF33B
The numbers on the left and right sides of a black line in the graphical overview indicate the lengths (in amino acid residues) of the non-homologous N-terminal and C-terminal portions flanking the homologous region (indicated by the black line), respectively.
Result of motif / domain search (InterProScan and SOSUI)
[ zoom out (x2) ] Result of InterProScan
Result of InterProScan
Search method interpro_ID From To Entry Definition HMMPfam IPR001909 12 52 PF01352 Krueppel-associated box IPR007087 384 406 PF00096 Zinc finger IPR007087 412 434 PF00096 Zinc finger IPR007087 440 462 PF00096 Zinc finger IPR007087 468 490 PF00096 Zinc finger IPR007087 496 518 PF00096 Zinc finger IPR007087 524 546 PF00096 Zinc finger IPR007087 552 574 PF00096 Zinc finger IPR007087 580 602 PF00096 Zinc finger IPR007087 608 630 PF00096 Zinc finger IPR007087 636 658 PF00096 Zinc finger IPR007087 720 742 PF00096 Zinc finger IPR007087 748 770 PF00096 Zinc finger HMMSmart IPR001909 12 72 SM00349 Krueppel-associated box IPR015880 328 350 SM00355 Zinc finger IPR015880 356 378 SM00355 Zinc finger IPR015880 384 406 SM00355 Zinc finger IPR015880 412 434 SM00355 Zinc finger IPR015880 440 462 SM00355 Zinc finger IPR015880 468 490 SM00355 Zinc finger IPR015880 496 518 SM00355 Zinc finger IPR015880 524 546 SM00355 Zinc finger IPR015880 552 574 SM00355 Zinc finger IPR015880 580 602 SM00355 Zinc finger IPR015880 608 630 SM00355 Zinc finger IPR015880 636 658 SM00355 Zinc finger IPR015880 664 686 SM00355 Zinc finger IPR015880 692 714 SM00355 Zinc finger IPR015880 720 742 SM00355 Zinc finger IPR015880 748 770 SM00355 Zinc finger ProfileScan IPR001909 12 83 PS50805 Krueppel-associated box IPR007087 328 355 PS50157 Zinc finger IPR007087 356 383 PS50157 Zinc finger IPR007087 384 411 PS50157 Zinc finger IPR007087 412 439 PS50157 Zinc finger IPR007087 440 467 PS50157 Zinc finger IPR007087 468 495 PS50157 Zinc finger IPR007087 496 523 PS50157 Zinc finger IPR007087 524 551 PS50157 Zinc finger IPR007087 552 579 PS50157 Zinc finger IPR007087 580 607 PS50157 Zinc finger IPR007087 608 635 PS50157 Zinc finger IPR007087 636 663 PS50157 Zinc finger IPR007087 664 691 PS50157 Zinc finger IPR007087 692 719 PS50157 Zinc finger IPR007087 720 747 PS50157 Zinc finger IPR007087 748 775 PS50157 Zinc finger
Result of homology search against disease genes in OMIM database(FASTA output,
Multiple alignment)
H_id H_len (aa) OMIM_No. ID (%) Q_ali/Q_len (%) NP_008905 810 194521 100.0 100.0 XP_011517953 810 194521 100.0 100.0 XP_011517952 811 194521 99.9 100.0 NP_008885 811 194521 99.9 100.0 NP_001265099 817 194521 100.0 99.6 Inquiries or Suggestions ?
Send a message to flexiclone AT kazusagt.comCloned ORF Nucleotide sequence for pF1KSDA0065 Download>KIAA0065 2430 bp ATGAACAAGGTAGAACAGAAGTCCCAGGAGTCAGTATCATTTAAAGATGTGACTGTGGGC TTCACCCAGGAGGAGTGGCAGCACCTGGACCCTAGTCAGAGGGCTCTGTATAGAGATGTG ATGCTGGAGAACTACAGCAACCTTGTCTCAGTGGGGTATTGTGTTCACAAACCAGAGGTG ATCTTCAGGCTGCAACAAGGAGAAGAGCCATGGAAACAGGAGGAAGAATTCCCAAGCCAA AGCTTTCCAGTCTGGACAGCTGATCACCTGAAAGAGAGGAGCCAAGAAAACCAATCTAAA CATTTGTGGGAAGTTGTATTCATCAATAATGAAATGCTGACTAAGGAACAAGGTGATGTA ATAGGAATACCATTTAATGTGGATGTAAGTTCTTTTCCTTCCAGAAAAATGTTCTGTCAG TGTGATTCATGTGGAATGAGTTTCAACACTGTTTCAGAATTGGTTATCAGTAAGATAAAC TATTTAGGAAAAAAGTCTGATGAATTTAATGCCTGTGGGAAATTGTTACTCAATATTAAG CATGATGAAACTCATACTCAAGAGAAAAATGAAGTTTTGAAAAATAGGAACACACTGAGT CATCATGAGGAGACTTTGCAGCATGAGAAGATTCAAACTTTAGAGCACAATTTTGAATAC AGTATATGTCAGGAAACCCTCCTTGAAAAGGCAGTATTCAATACACAGAAGAGAGAGAAC GCAGAAGAGAATAACTGTGATTATAATGAATTTGGGAGAACTTTGTGTGATAGTTCATCC CTCTTGTTCCATCAGATATCTCCGTCAAGGGACAATCACTATGAATTTAGTGATTGTGAG AAGTTCTTATGTGTGAAGTCCACCCTTTCTAAACCTCATGGGGTATCTATGAAACACTAT GATTGTGGTGAAAGTGGGAATAATTTCAGGAGGAAATTGTGTCTGTCACACCTTCAGAAA GGTGATAAAGGAGAGAAACACTTTGAATGTAATGAATGTGGGAAAGCTTTCTGGGAGAAG TCACATCTCACTCGACATCAGAGGGTGCACACAGGACAGAAACCCTTTCAATGTAATGAA TGTGAAAAAGCTTTCTGGGATAAGTCAAACCTCACTAAACATCAAAGATCACACACAGGG GAGAAACCTTTTGAATGCAATGAATGTGGGAAAGCCTTTAGCCATAAGTCAGCCCTCACA TTACACCAGAGAACACATACAGGGGAGAAACCCTATCAATGTAATGCGTGTGGGAAAACT TTTTGCCAGAAATCTGACCTCACTAAACATCAGAGAACACACACAGGGCTGAAACCCTAT GAATGTTATGAATGTGGAAAATCCTTCCGTGTGACTTCGCACCTTAAAGTACACCAGAGA ACTCACACAGGTGAGAAACCTTTTGAATGTCTTGAGTGTGGGAAATCCTTTAGTGAAAAG TCAAATCTTACACAGCATCAGAGAATTCACATAGGAGATAAATCTTATGAATGTAATGCA TGTGGGAAAACTTTCTACCACAAGTCATTACTCACCAGGCATCAGATAATTCATACAGGG TGGAAACCTTATGAATGTTATGAATGTGGGAAAACCTTCTGCTTGAAGTCAGACCTCACA GTACATCAGAGAACACACACAGGGCAGAAACCCTTTGCATGTCCCGAATGTGGGAAATTC TTTAGCCATAAGTCAACCCTCTCTCAACATTATAGAACACACACAGGGGAGAAACCCTAC GAATGTCATGAATGTGGAAAAATCTTTTACAATAAATCATACCTAACTAAACATAATAGA ACACATACAGGGGAGAAACCCTATGAATGTAATGAATGTGGAAAAGCCTTCTACCAGAAG TCACAACTCACTCAGCATCAGAGAATTCACATAGGGGAGAAACCCTATAAATGTAATGAG TGTGGAAAAGCTTTCTGCCATAAGTCAGCTCTAATTGTACATCAGAGAACCCATACACAA GAAAAGCCCTATAAATGTAATGAATGTGGAAAATCTTTCTGTGTAAAATCAGGACTTATT TTCCATGAGAGAAAGCACACGGGGGAGAAACCCTATGAATGCAATGAATGTGGGAAATTC TTCAGGCACAAATCATCACTCACAGTACATCACAGGGCTCACACAGGAGAGAAATCTTGT CAATGTAATGAATGTGGAAAAATCTTTTACCGTAAATCGGAACTTGCTCAACATCAGAGA TCACATACAGGGGAAAAGCCCTATGAATGTAACACATGCAGGAAAACTTTCTCTCAAAAG TCAAATCTCATTGTACATCAGAGAAGACATATAGGAGAAAACCTTATGAATGAAATGGAT ATTAGAAATTTCCAGCCACAAGTCAGCCTCCATAATGCCTCAGAGTATTCACACTGTGGA GAAAGCCCTGATGACATCCTGAATGTTCAG
Cloned ORF protein sequence for pF1KSDA0065 Download>KIAA0065 810 aa MNKVEQKSQESVSFKDVTVGFTQEEWQHLDPSQRALYRDVMLENYSNLVSVGYCVHKPEV IFRLQQGEEPWKQEEEFPSQSFPVWTADHLKERSQENQSKHLWEVVFINNEMLTKEQGDV IGIPFNVDVSSFPSRKMFCQCDSCGMSFNTVSELVISKINYLGKKSDEFNACGKLLLNIK HDETHTQEKNEVLKNRNTLSHHEETLQHEKIQTLEHNFEYSICQETLLEKAVFNTQKREN AEENNCDYNEFGRTLCDSSSLLFHQISPSRDNHYEFSDCEKFLCVKSTLSKPHGVSMKHY DCGESGNNFRRKLCLSHLQKGDKGEKHFECNECGKAFWEKSHLTRHQRVHTGQKPFQCNE CEKAFWDKSNLTKHQRSHTGEKPFECNECGKAFSHKSALTLHQRTHTGEKPYQCNACGKT FCQKSDLTKHQRTHTGLKPYECYECGKSFRVTSHLKVHQRTHTGEKPFECLECGKSFSEK SNLTQHQRIHIGDKSYECNACGKTFYHKSLLTRHQIIHTGWKPYECYECGKTFCLKSDLT VHQRTHTGQKPFACPECGKFFSHKSTLSQHYRTHTGEKPYECHECGKIFYNKSYLTKHNR THTGEKPYECNECGKAFYQKSQLTQHQRIHIGEKPYKCNECGKAFCHKSALIVHQRTHTQ EKPYKCNECGKSFCVKSGLIFHERKHTGEKPYECNECGKFFRHKSSLTVHHRAHTGEKSC QCNECGKIFYRKSELAQHQRSHTGEKPYECNTCRKTFSQKSNLIVHQRRHIGENLMNEMD IRNFQPQVSLHNASEYSHCGESPDDILNVQ
Nucleotide Sequence (with vector) for pF1KSDA0065 Download>pF1KSDA0065 5567 bp GGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAA TTCCCCACTAGTAATAATTTTCTTTAACTTTAGTAAGGAGCGATCGCTTTCGAAGGAGAT AGAACCATGAACAAGGTAGAACAGAAGTCCCAGGAGTCAGTATCATTTAAAGATGTGACT GTGGGCTTCACCCAGGAGGAGTGGCAGCACCTGGACCCTAGTCAGAGGGCTCTGTATAGA GATGTGATGCTGGAGAACTACAGCAACCTTGTCTCAGTGGGGTATTGTGTTCACAAACCA GAGGTGATCTTCAGGCTGCAACAAGGAGAAGAGCCATGGAAACAGGAGGAAGAATTCCCA AGCCAAAGCTTTCCAGTCTGGACAGCTGATCACCTGAAAGAGAGGAGCCAAGAAAACCAA TCTAAACATTTGTGGGAAGTTGTATTCATCAATAATGAAATGCTGACTAAGGAACAAGGT GATGTAATAGGAATACCATTTAATGTGGATGTAAGTTCTTTTCCTTCCAGAAAAATGTTC TGTCAGTGTGATTCATGTGGAATGAGTTTCAACACTGTTTCAGAATTGGTTATCAGTAAG ATAAACTATTTAGGAAAAAAGTCTGATGAATTTAATGCCTGTGGGAAATTGTTACTCAAT ATTAAGCATGATGAAACTCATACTCAAGAGAAAAATGAAGTTTTGAAAAATAGGAACACA CTGAGTCATCATGAGGAGACTTTGCAGCATGAGAAGATTCAAACTTTAGAGCACAATTTT GAATACAGTATATGTCAGGAAACCCTCCTTGAAAAGGCAGTATTCAATACACAGAAGAGA GAGAACGCAGAAGAGAATAACTGTGATTATAATGAATTTGGGAGAACTTTGTGTGATAGT TCATCCCTCTTGTTCCATCAGATATCTCCGTCAAGGGACAATCACTATGAATTTAGTGAT TGTGAGAAGTTCTTATGTGTGAAGTCCACCCTTTCTAAACCTCATGGGGTATCTATGAAA CACTATGATTGTGGTGAAAGTGGGAATAATTTCAGGAGGAAATTGTGTCTGTCACACCTT CAGAAAGGTGATAAAGGAGAGAAACACTTTGAATGTAATGAATGTGGGAAAGCTTTCTGG GAGAAGTCACATCTCACTCGACATCAGAGGGTGCACACAGGACAGAAACCCTTTCAATGT AATGAATGTGAAAAAGCTTTCTGGGATAAGTCAAACCTCACTAAACATCAAAGATCACAC ACAGGGGAGAAACCTTTTGAATGCAATGAATGTGGGAAAGCCTTTAGCCATAAGTCAGCC CTCACATTACACCAGAGAACACATACAGGGGAGAAACCCTATCAATGTAATGCGTGTGGG AAAACTTTTTGCCAGAAATCTGACCTCACTAAACATCAGAGAACACACACAGGGCTGAAA CCCTATGAATGTTATGAATGTGGAAAATCCTTCCGTGTGACTTCGCACCTTAAAGTACAC CAGAGAACTCACACAGGTGAGAAACCTTTTGAATGTCTTGAGTGTGGGAAATCCTTTAGT GAAAAGTCAAATCTTACACAGCATCAGAGAATTCACATAGGAGATAAATCTTATGAATGT AATGCATGTGGGAAAACTTTCTACCACAAGTCATTACTCACCAGGCATCAGATAATTCAT ACAGGGTGGAAACCTTATGAATGTTATGAATGTGGGAAAACCTTCTGCTTGAAGTCAGAC CTCACAGTACATCAGAGAACACACACAGGGCAGAAACCCTTTGCATGTCCCGAATGTGGG AAATTCTTTAGCCATAAGTCAACCCTCTCTCAACATTATAGAACACACACAGGGGAGAAA CCCTACGAATGTCATGAATGTGGAAAAATCTTTTACAATAAATCATACCTAACTAAACAT AATAGAACACATACAGGGGAGAAACCCTATGAATGTAATGAATGTGGAAAAGCCTTCTAC CAGAAGTCACAACTCACTCAGCATCAGAGAATTCACATAGGGGAGAAACCCTATAAATGT AATGAGTGTGGAAAAGCTTTCTGCCATAAGTCAGCTCTAATTGTACATCAGAGAACCCAT ACACAAGAAAAGCCCTATAAATGTAATGAATGTGGAAAATCTTTCTGTGTAAAATCAGGA CTTATTTTCCATGAGAGAAAGCACACGGGGGAGAAACCCTATGAATGCAATGAATGTGGG AAATTCTTCAGGCACAAATCATCACTCACAGTACATCACAGGGCTCACACAGGAGAGAAA TCTTGTCAATGTAATGAATGTGGAAAAATCTTTTACCGTAAATCGGAACTTGCTCAACAT CAGAGATCACATACAGGGGAAAAGCCCTATGAATGTAACACATGCAGGAAAACTTTCTCT CAAAAGTCAAATCTCATTGTACATCAGAGAAGACATATAGGAGAAAACCTTATGAATGAA ATGGATATTAGAAATTTCCAGCCACAAGTCAGCCTCCATAATGCCTCAGAGTATTCACAC TGTGGAGAAAGCCCTGATGACATCCTGAATGTTCAGTACGTAGTTTAAACGAATTCGAGC TCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTGATCCGGCTGCTAA CAAAGCCCGAAAGGAAGCTGAGTTGGCTGCTGCCACCGCTGAGCAATAACTAGCATAACC CCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTGAAAGGAGGAACTATATCCGG TTCGCTTGCTGTCCATAAAACCGCCCAGTCTAGCTATCGCCATGTAAGCCCACTGCAAGC TACCTGCTTTCTCTTTGCGCTTGCGTTTTCCCTTGTCCAGATAGCCCAGTAGCTGACATT CATCCGGGGTCAGCACCGTTTCTGCGGACTGGCTTTCTACGTGTTCCGCTTCCTTTAGCA GCCCTTGCGCCCTGAGTGCTTGCGGCAGCGTGAGCTTCAAAAGAATTGCCAGCTGGGGCG CCCTCTGGTAAGGTTGGGAAGCCCTGCAAAGTAAACTGGATGGCTTTCTTGCCGCCAAGG ATCTGATGGCGCAGGGGATCAAGATCTGATCAAGAGACAGGATGACGGTCGTTTCGCATG CTTGAACAAGATGGATTGCACGCAGGTTCTCCGGCCGCTTGGGTGGAGAGGCTATTCGGC TATGACTGGGCACAACAGACAATCGGCTGCTCTGATGCCGCCGTGTTCCGGCTGTCAGCG CAGGGGCGCCCGGTTCTTTTTGTCAAGACCGACCTGTCCGGTGCCCTGAATGAACTGCAG GACGAGGCAGCGCGGCTATCGTGGCTGGCCACGACGGGCGTTCCTTGCGCAGCTGTGCTC GACGTTGTCACTGAAGCGGGAAGGGACTGGCTGCTATTGGGCGAAGTGCCGGGGCAGGAT CTCCTGTCATCTCACCTTGCTCCTGCCGAGAAAGTATCCATCATGGCTGATGCAATGCGG CGGCTGCATACGCTTGATCCGGCTACCTGCCCATTCGACCACCAAGCGAAACATCGCATC GAGCGAGCACGCACTCGGATGGAAGCCGGTCTTGTCGATCAGGATGATCTGGACGAAGAG CATCAGGGGCTCGCGCCAGCCGAACTGTTCGCCAGGCTCAAGGCGCGTATGCCGGATGGT GAGGATCTCGTCGTGACTCATGGCGATGCCTGCTTGCCGAATATCATGGTGGAAAATGGC CGCTTTTCTGGATTCATCGACTGTGGCCGGCTGGGTGTGGCGGACCGCTATCAGGACATA GCGTTGGCTACCCGTGATATTGCTGAAGAGCTTGGCGGCGAATGGGCTGACCGCTTCCTC GTGCTTTACGGTATCGCCGCTCCCGATTCGCAGCGCATCGCCTTCTATCGCCTTCTTGAC GAGTTCTTCTGAGCGGGACTCTGGGGTTCGAAATGACCGACCAAGCGACGCCCAACCGGT ATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAA GAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGC GTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAG GTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGT GCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGG AAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCG CTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGG TAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCAC TGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTG GCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGT TACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGG TGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATTTCAAGAAGATCC TTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTT GGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTATAGTCCGGAAATACAGG AACGCACGCTGGATGGCCCTTCGCTGGGATGGTGAAACCATGAAAAATGGCAGCTTCAGT GGATTAAGTGGGGGTAATGTGGCCTGTACCCTCTGGTTGCATAGGTATTCATACGGTTAA AATTTATCAGGCGCGATTGCGGCAGTTTTTCGGGTGGTTTGTTGCCATTTTTACCTGTCT GCTGCCGTGATCGCGCTGAACGCGTTTTAGCGGTGCGTACAATTAAGGGATTATGGTAAA TCCACTTACTGTCTGCCCTCGTAGCCATCGAGATAAACCGCAGTACTCCGGCCACGATGC GTCCGGCGTAGAGGATCGAGATCTTTTCAGCCTGATACAGATTAAATCAGAACGCAGAAG CGGTCTGATAAAACAGAATTTGCCTGGCGGCAGTAGCGCGGTGGTCCCACCTGACCCCAT GCCGAACTCAGAAGTGAAACGCCGTAGCGCCGATGGTAGTGTGGGGTCTCCCCATGCGAG AGTAGGGAACTGCCAGGCATCAAATAAAACGAAAGGCTCAGTCGAAAGACTGGGCCTTTC GTTTTATCTGTTGTTTGTCGGTGAACGCTCTCCTGAGTAGGACAAATCCGCCGGGAGCGG ATTTGAACGTTGCGAAGCAACGGCCCGGAGGGTGGCGGGCAGGACGCCCGCCATAAACTG CCAGGCATCAAATTAAGCAGAAGGCCATCCTGACGGATGGCCTTTTTGCGTTTCTACAAA CTCTTTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCAT
 more Linker info
more Linker info
{kind=link}